Paper Review - [ICLR 2024] “SuRe ; Summarizing Retrievals using Answer Candidates for Open-Domain QA of LLMs”, Jaehyung Kim et al., 16 Jan 2024
Conference : ICLR (The International Conference on Learning Representations), 2024
1. Contributions
본 논문에서는 LLM(Large Language Model)의 QA(Question-Answering) task 성능을 향상시키는 것에 있어서, 정답에 연관이 있는 문단들을 retrieving하여 prompting하는 RAG System이 큰 역할을 했다고 합니다. 그럼에도 LLM은 Retrieving을 잘 하도록 학습된 것이 아니라, 이를 활용하도록 지시를 받을 뿐이므로, 단순한 Prompting으로는 Retrieved Passages를 충분히 활용하기에 한계가 있다고 합니다. 또한, Retrieving한 passage가 너무 긴 경우에는 Input Prompt가 너무 길어져 발생하는 한계도 있으며, Model을 fine-tuning하기에도 최근의 LLM들 중 black-box API가 많아 한계가 있다고 합니다. 본 논문에서는 이러한 한계들을 극복하기 위한 Prompting을 하는 방법을 제안했으며, ODQA에서의 RAG System의 성능을 개선하는 SuRe(Summarized Retrieval)를 소개했습니다. SuRe의 핵심 기여는 다음과 같습니다.
- Enhancing Accuracy : SuRe는 관련 문서의 요약 검색을 통해 보다 잘 뒷받침된 근거를 제공함으로써 ODQA System에서 답변 예측의 정확성을 향상시켰습니다.
- Various Platforms : SuRe는 다양한 검색 방법과 LLM 구성과 호환될 수 있도록 설계되었습니다. 이로 인해 SuRe는 다양한 설정에서 사용할 수 있으며, Black-box API 접근만 제공하는 다양한 platform과 LLM에도 유용하고 확장 가능하게 만듭니다.
- Zero-Shot Prompting : SuRe는 zero-shot prompting을 통해 작동하며, 특정 쿼리 관련 예시와 함께 추가적인 fine-tuning이나 training이 필요 없습니다. 이는 SuRe의 배포 및 운영 과정을 크게 단순화하여, 빠르고 효율적인 구현을 가능하도록 합니다.
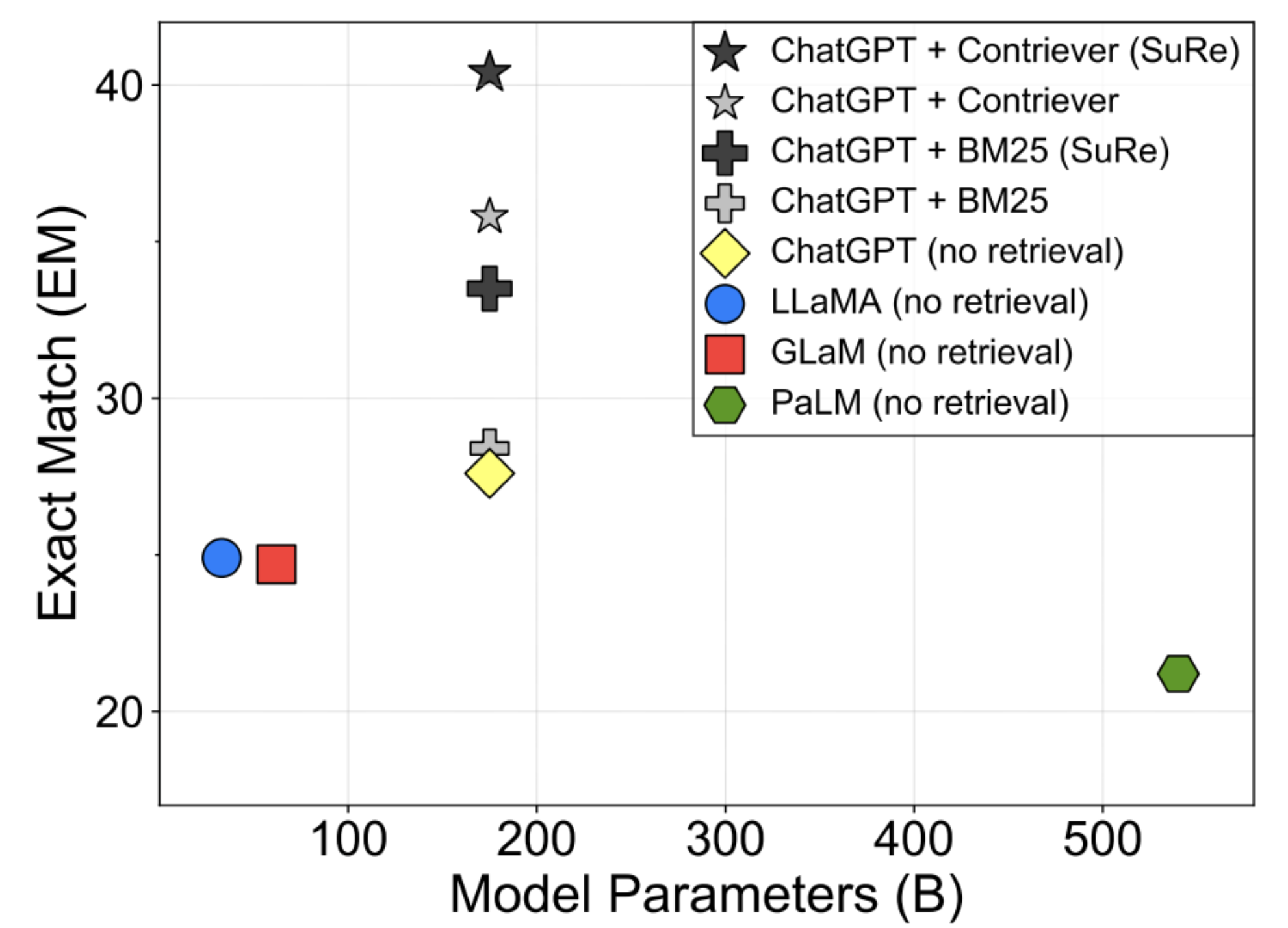
첨부된 이미지를 통해 확인할 수 있듯이, SuRe를 적용한 것의 EM Score가 높다는 것을 알 수 있습니다. BM25와 Contriever에 대한 내용은 다음 목차에서 다루겠습니다.
2. Backgrounds
2-1. Retriever
RAG System에서 Retriever는 Query에 대한 답변을 생성하기에 도움이 되는 external knowledge를 검색해오는 module입니다. Retriever의 종류로는 크게 Lexical-based retriever와 Embedding-based retriever로 나눌 수 있습니다.
2-1-1. Lexical-based retriever
Lexical-based로는 TF-IDF와 BM25가 있습니다.
- TF-IDF : TF-IDF(Term Frequency-Inverse Document Frequency)는 단어가 문서 내에서 얼마나 자주 등장하는지와 그 단어가 얼마나 희귀한지를 고려하여 단어의 중요도를 평가하는 방법입니다. TF는 단어 빈도, IDF는 역문서 빈도로 계산되며, 이 두 값의 곱으로 각 단어의 가중치를 결정합니다.
- BM25 : BM25(Best Matching 25)는 TF-IDF의 개선 버전으로, 각 단어의 빈도와 역문서 빈도를 고려하여 문서의 관련성을 평가합니다. BM25는 문서 내 단어의 빈도가 증가함에 따라 로그함수를 사용하여 가중치를 부여하고, 문서의 길이가 길어질수록 페널티를 부여하여 긴 문서의 단어 빈도가 과대평가되는 것을 방지합니다.
2-1-2. Embedding-based retriever
Embedding-based로는 DPR과 Contriever가 있습니다.
- DPR : DPR(Dense Passage Retrieval)은 문서와 질의어를 독립적으로 embedding하여 cosine similarity를 통해 가장 관련성 높은 문서를 찾습니다. DPR은 특히 ODQA(Open Domain Question-Answering)에 효과적으로 사용되며, 각 문서의 의미를 포착하는 데 중점을 둔 BERT 같은 사전 훈련된 언어 모델을 사용합니다.
- Contriever : Contriever는 Contrastive Retriever의 약자로, 대조 학습을 통해 Query와 Document 사이의 Semantic Similarity을 향상시키는 방법입니다. 이 방법은 DPR과 유사하게 작동하지만, model이 각 query에 대해 양성(관련 있는) 예시와 음성(관련 없는) 예시를 비교하면서 학습하므로, 더 높은 성능을 발휘할 수 있습니다.
이와 같이 Retriever는 External Knowledge을 검색하는 역할을 수행하고, 검색된 정보를 종합하고 추론하는 역할은 Reader module이 담당합니다. 최근에는 Reader module로 BERT나 T5 같은 LLM을 fine-tuning하여 사용하는 경우가 많습니다.
3. Methodology
3-1. Overview and Problem Description
본 논문에서의 핵심 idea는 retrieved passages를 통해 여러 개의 Summary를 만들고 활용한다는 것에 있습니다. Summary를 생성하기 전에 retrieved document를 토대로 정답에 대한 candidates를 만든 이후에, 이 candidate를 조건부로 하여 summary를 생성합니다. 즉, candidate answer와 관련된 summary들을 만들고, 해당 summary들 각각의 타당성과 관련된 정보가 잘 담겨있는지 평가하는 방식으로 answer를 찾아내게 됩니다.
\[C_{N}^{+} = \text{Retriever}(q, C, N) \quad \text{and} \quad \hat{a} = \text{Reader}(q, C_{N}^{+})\]where,
$C$ : Whole corpus
$C_{N}^{+}$ : Informative passages
$\hat{a}$ : The predicted answer
$N$ : The number of retrieved passages
본 논문에서는 Retriever method로 BM25와 Contriever를 모두 활용하여 비교하였고, Reader module로 ChatGPT나 LLaMa-2(7B, 13B)와 같은 LLM을 활용했다고 합니다. 구체적인 Prompting 방법은 다음과 같습니다.
Prompt $p(q, C_{N}^{+})$ = $“\text{Reading Passages} \enspace C_{N}^{+},\enspace \text{answer to question} \enspace q”$
$\hat{a} = M(p(q, C_{N}^{+}))$, $M$ is LLM
이제 각각의 candidate answer와 candidate-conditioned summarization을 어떻게 수행하는지 살펴보도록 하겠습니다.
3-1-1. Candidates generation
본 논문에서는 Query $q$와 retrieved passages $C_{N}^{+}$ 그리고 LLM $M$을 활용하여 answer candidates \(\tilde{y} = [\tilde{y}_1, \ldots, \tilde{y}_K]\)를 생성한다고 합니다. 이 때, prompt $p_{can}$을 활용한다고 합니다. prompt $p_{can}$은 아래와 같습니다.
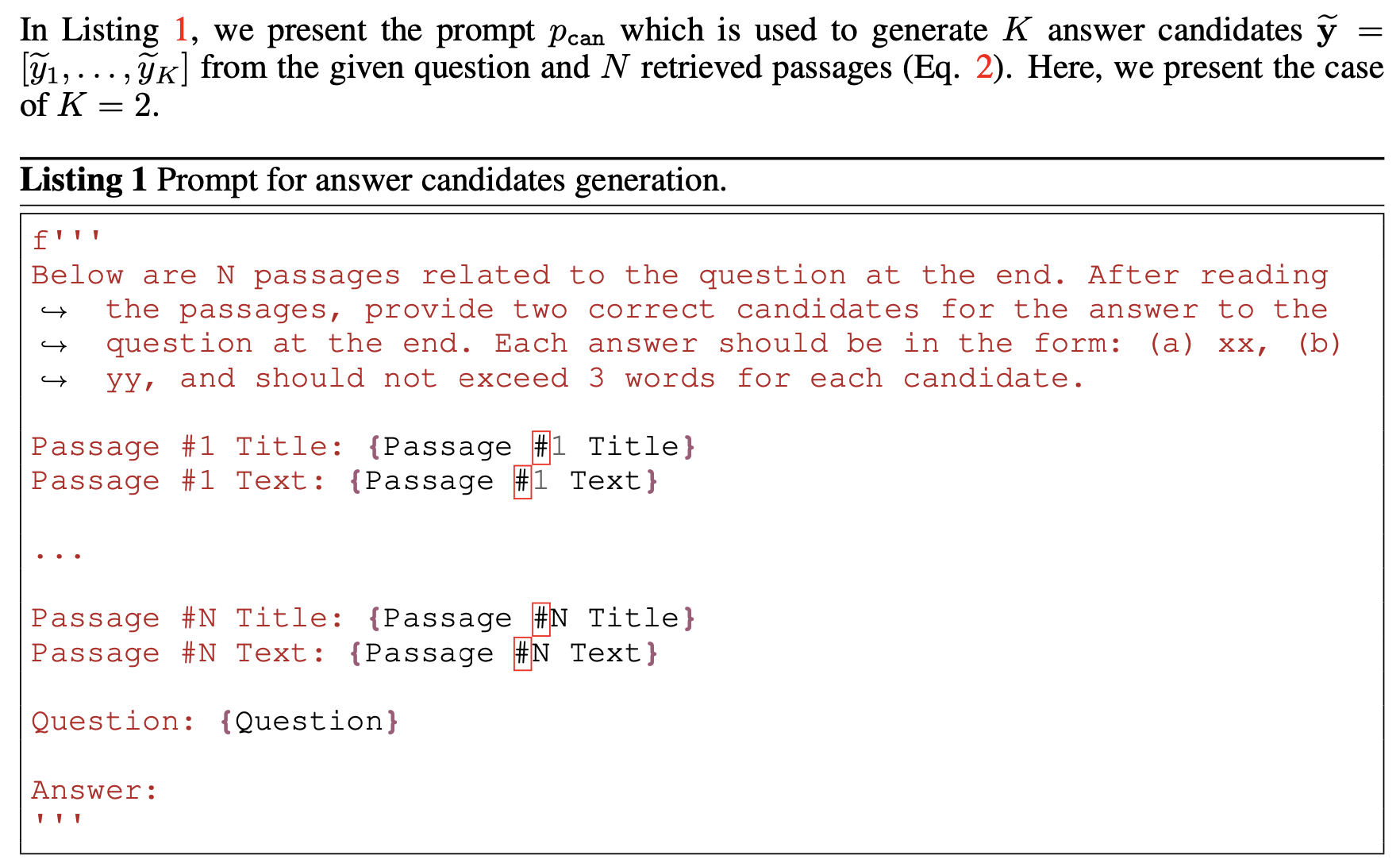
위 Prompt를 통해서 알 수 있듯이, 기존에는 Retrieved passages를 통해서 하나의 답변만 생성했다면, 본 논문에서는 두 개의 answer candidates를 생성한다는 것을 알 수 있습니다. 예시에서는 2개의 candidates만을 생성했지만, 쉽게 더 많은 candidates를 생성할 수 있습니다. 수식으로는 다음과 같이 표현됩니다.
\[\tilde{y} = M(p_{can}(q, C_{N}^{+}))\]3-1-2. Candidate-conditioned summarization
그 다음으로는 answer candidates를 활용하여 각각의 candidate에 대응되는 summary를 생성하게 됩니다.
\[s_k = M(P_{sum}(q, C_{N}^{+}, y_k) \enspace \text{for} \enspace k = 1, \ldots, K\]where
$s_k$ : Conditional summarization
$y_k$ : answer candidate, $\tilde{y}_k \in \tilde{y}$
$p_{sum}$ : Prompt to obtain the conditional summarization $s_k$
prompt $p_{sum}$은 아래와 같습니다.
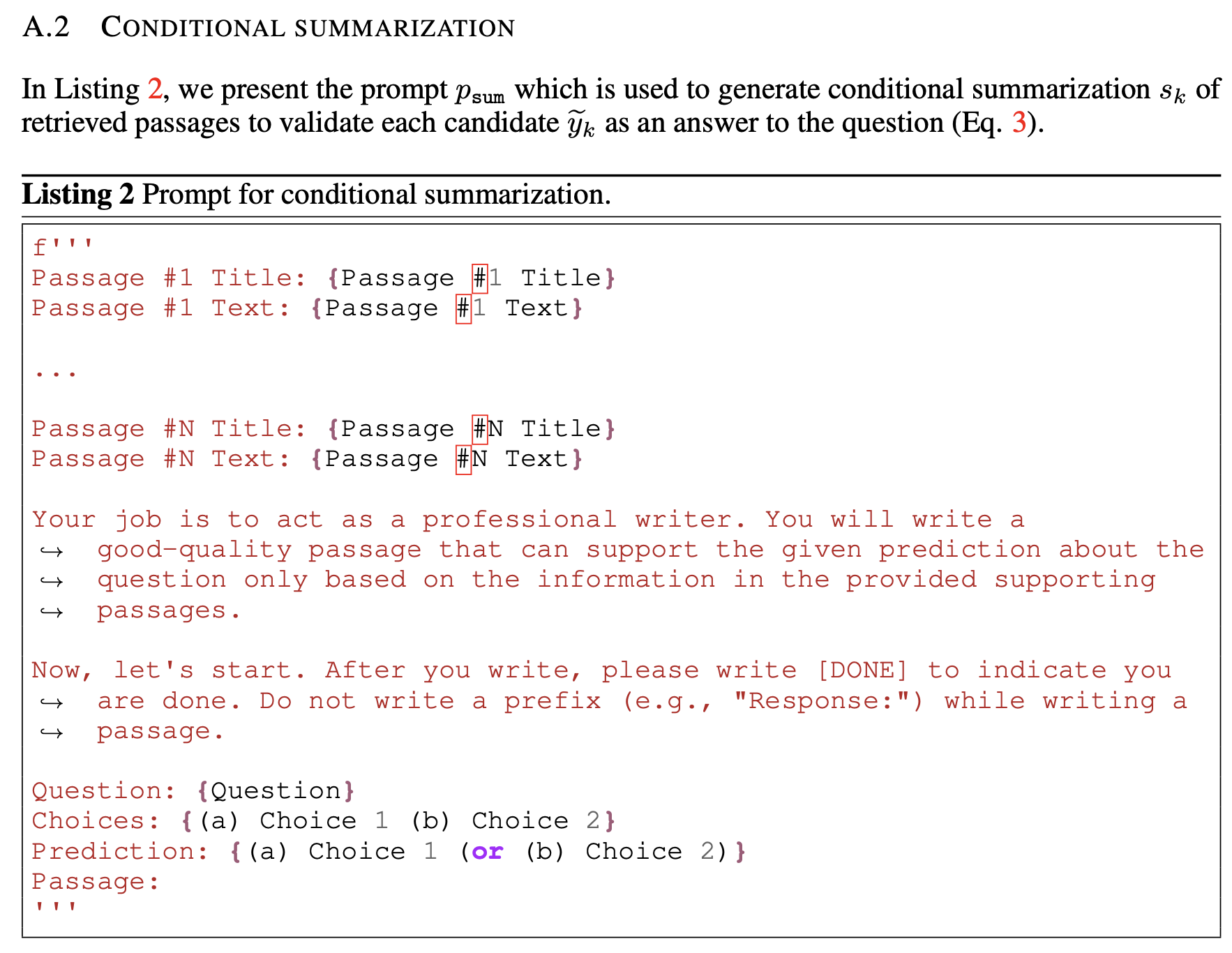
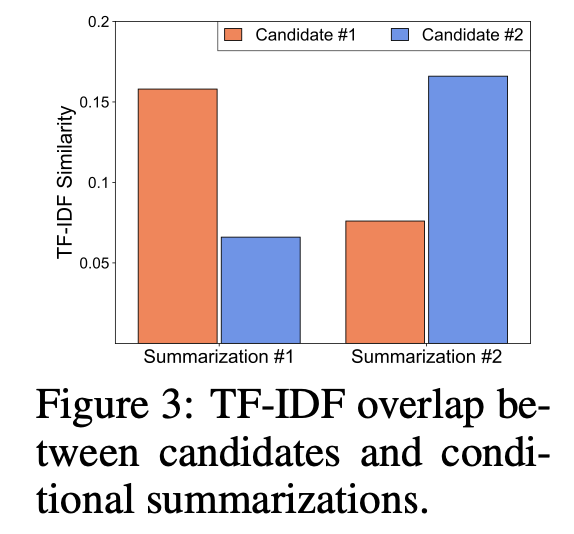
위와 같은 prompting기법으로 summary를 생성한 결과 아래와 같이, 각 Candidate에 대한 summary의 TF-IDF Similarity가 높게 나온 것을 통해 summary가 잘 생성되었다는 것을 알 수 있습니다. 또한, retrieved passages에 총 1000개의 단어가 있다고 했을 때, summary를 활용한다면 90개의 단어로 context size를 비약적으로 줄일 수 있었다고 합니다. 이는 현재 LLM이 갖고 있는 고질적인 한계인 Context window에 대해 robust하다는 것을 의미합니다.
결과적으로, 위의 방식들을 통해 Prediction을 어떻게 하게 되는지 아래의 사진을 통해서 구체적인 예시를 살펴볼 수 있습니다.

3-2. Selective Prediction Via Verification of Summarizations
3-1에서 생성한 Summary들을 통해 Candidates 사이에서 가장 적절한 답변을 찾는 과정을 살펴보겠습니다. 본 논문에서 핵심적으로 다룬 부분은 생성된 summary의 quality입니다. 논문에서는 이 quality를 factuality, logicality, readability로 정의했습니다. 해당 부분들을 고려하여, SuRe Algorithm을 통해서 최종 정답을 추론한다고 합니다. SuRe Algorithm은 다음과 같습니다.

위 Algorithm에서 1, 2, 3은 3-1에서 다루었으므로, 4: Instance-wise Validation과 5: Pair-wise Ranking에 대해서 살펴보도록 하겠습니다.
3-2-1. Instance-wise Validation
Instance-wise Validation에서는 생성된 각각의 summary $s_k$가 정답 후보 \(\tilde{y}_k\)를 다른 정답 후보 \(\tilde{y}_i, i \neq k\) 보다 잘 지지하고 있는지를 판단합니다. 논문에서는 Prompt $p_{val}$ 를 활용하여 validity $v_k$를 생성한다고 합니다.
\[v(s_k) = 1, \text{when} \enspace M(p_{val}(q,y_k, s_k)) = \text{True} \enspace or \enspace v(s_k) = 0 , \enspace \text{else}\]Prompt $p_{val}$은 아래와 같습니다.

3-2-2. Pair-wise Ranking
Pair-wise Ranking에서는 summary $s_k$가 query $q$에 대한 답변을 생성하는 것에 있어서 다른 모든 summries \(S_k = \{s_k\}_{k=1}^K\)에 비해 상대적으로 informative한지를 평가한다고 합니다. 이를 위해서, 본 논문에서는 아래와 같은 방식으로 ranking $r_k$를 계산했습니다.
\[r(s_k, S_K) = \sum_{i \neq k}^{K} r_{\text{pair}}(s_k, s_i)\] \[r_{\text{pair}}(s_k, s_i) = \begin{cases} 1 & \text{if } \mathcal{M}(p_{\text{rank}}(q, s_k, s_i)) = s_k \\0 & \text{if } \mathcal{M}(p_{\text{rank}}(q, s_k, s_i)) = s_i \\0.5 & \text{else}\end{cases}\]위의 수식을 보면, prompt $p_{rank}$를 통해서 어떤 summary가 query에 대한 답변을 생성하기에 더욱 적절한지 판단한다고 합니다. 결과적으로 위에서 얻은 ranking $r_k$를 활용하여 아래와 같은 방식으로 최종 answer를 결정한다고 합니다.
\[\hat{a} = \tilde{y}_{k*}, \enspace k^* = \text{argmax}_k v(s_k) + r(s_k, S_K)\]Prompt $p_{rank}$는 다음과 같습니다.
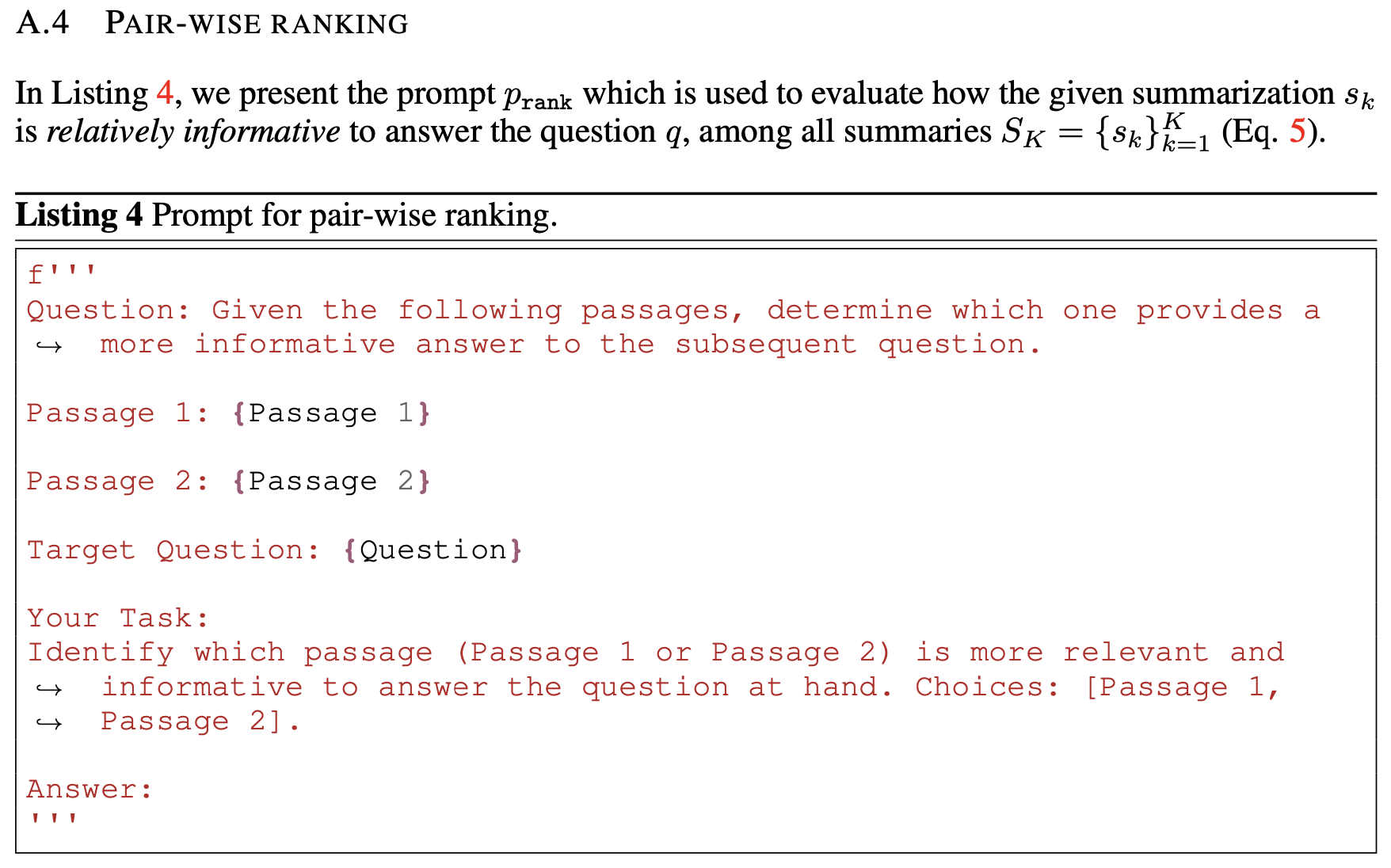
4. Empirical Results
본 논문에서는 SuRe를 검증하는 과정에 있어서 아래 4가지를 기준으로 실험했다고 합니다.
- SuRe가 ODQA dataset에서 LLM의 성능을 개선하였는가?
- SuRe가 다양한 retrieval methods와 LLMs에 대해서 적용이 가능한가?
- SuRe의 각각의 구성요소들의 효과는 어떠했는가?
- SuRe의 summary가 답변에 대해서 타당했는가?
먼저, 논문에서 활용한 Dataset은 1) Natural Questions(NQ), 2) WebQusetions(WebQ), 3) 2WikiMulti-hopQA (2Wiki), and 4) HoptopQA 로 4가지를 활용했다고 합니다.
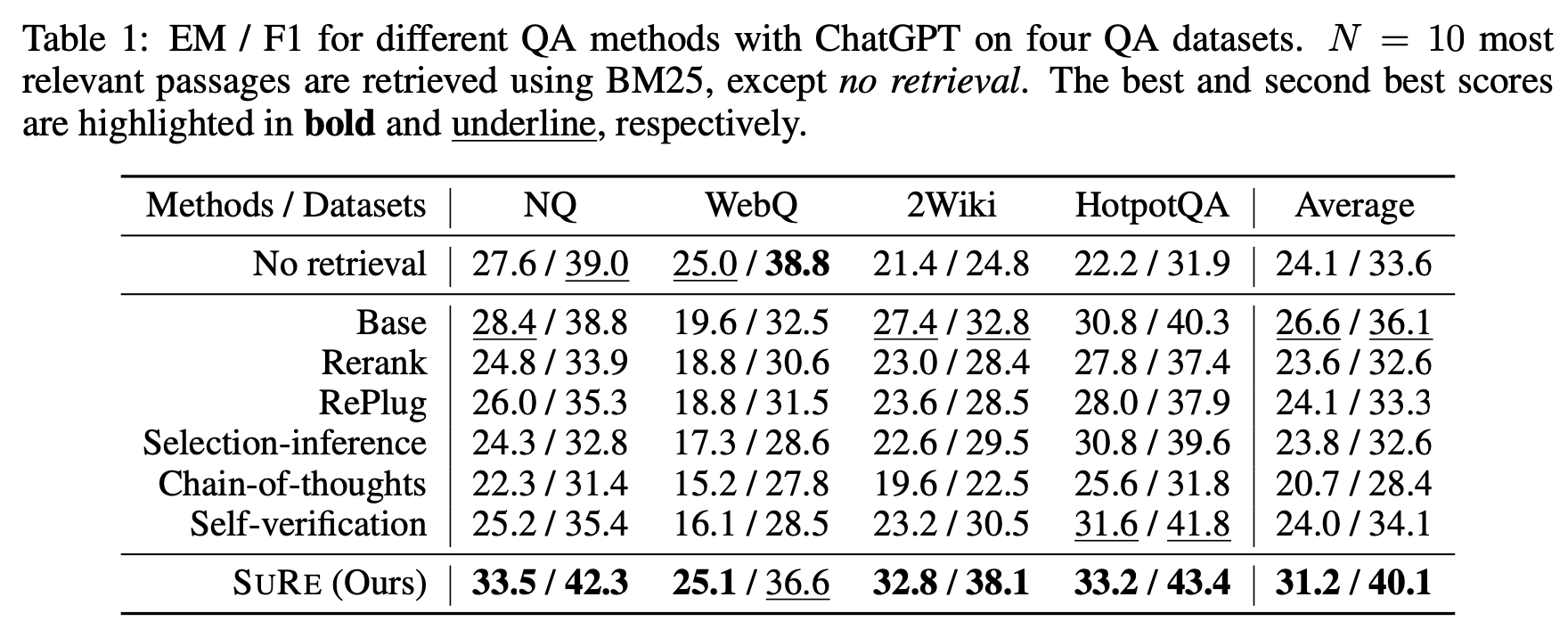
Table을 통해 확인할 수 있듯이, SuRe가 다른 방법론들에 비해서 성능이 더욱 우수했음을 확인할 수 있습니다.
실험 setting :
- SOTA LLMs : Chat GPT 3.5 Turbo, Chat GPT 4.0, LLaMa2-chat-70B with temperature 0
- Retrieval Methods : BM25(Elasticsearch), DPR-multi(BEIR), Contriever(BEIR)
- Number of answer candidates $K$ = 2
위의 setting에서 temperature는 쉽게 말해 LLM이 일관적이게 답변을 생성할 수 있도록 하는 setting이라고 볼 수 있습니다. 실험에서 API를 통해 LLM을 불러올 때, 웬만하면 temperature는 0으로 설정하게 됩니다.
또한, “Elasticsearch”와 “BEIR”은 정보 검색 분야에서 주요한 역할을 하는 도구와 벤치마크입니다. 여기에서 “Elasticsearch”는 실시간 데이터 검색 및 분석을 위한 Open source 검색 엔진으로, 대규모 데이터셋에서 빠르고 확장 가능한 검색 기능을 제공합니다. 이는 텍스트, 숫자 데이터 등 다양한 유형의 데이터를 처리할 수 있으며, 분산 환경에서의 확장성과 속도가 강점입니다. “BEIR” (Benchmarking IR)는 정보 검색 시스템의 성능을 평가하기 위한 benchmark입니다. 다양한 domain에서의 QA, Retrieving, IR 등의 task를 포함하여, 검색 system의 범용성과 효과성을 평가합니다. BEIR는 다양한 정보 검색 model과 algorithm을 통합하고 비교 분석할 수 있도록 다양한 dataset과 평가 기준을 제공합니다.
마지막으로 $K$는 정답 후보군의 갯수인데, 실험에서 K가 커짐에 따라 한계가 발생하여 2로 설정한 다음에 실험했다고 합니다.
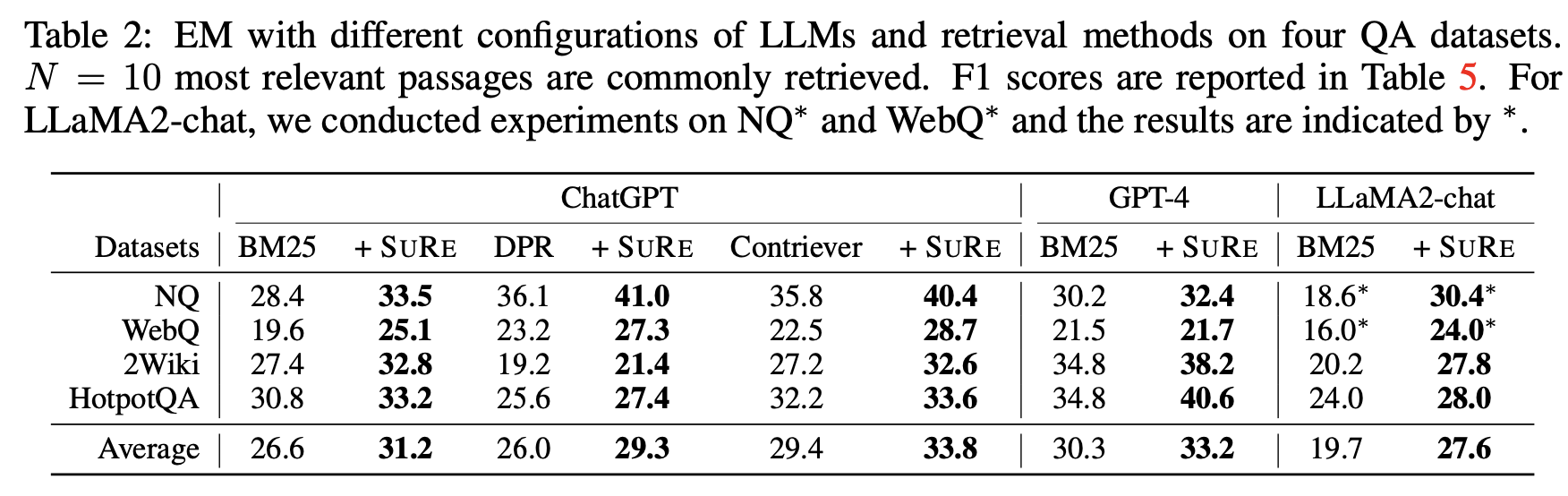
위의 setting을 통해서 실험을 한 결과 EM(Exact Matching) Score에 있어서 SuRe를 통해 retrieved passages를 활용한 것들의 결과가 가장 좋았습니다. 특히 average를 통해 Contriever + SuRe가 SOTA의 성능을 보여준다는 것을 알 수 있습니다. 한 가지 위의 table에서 흥미로운 점은 각각의 Dataset에 따라서 BM25, DPR, Contriever 사이에서 잘 작동하는 것이 있다는 점입니다. 이러한 사실을 통해 모든 Dataset에 대해서 포괄적으로 잘 작동하는 retriever를 고안해내는 것도 좋은 연구 주제가 될 수 있다고 생각합니다.
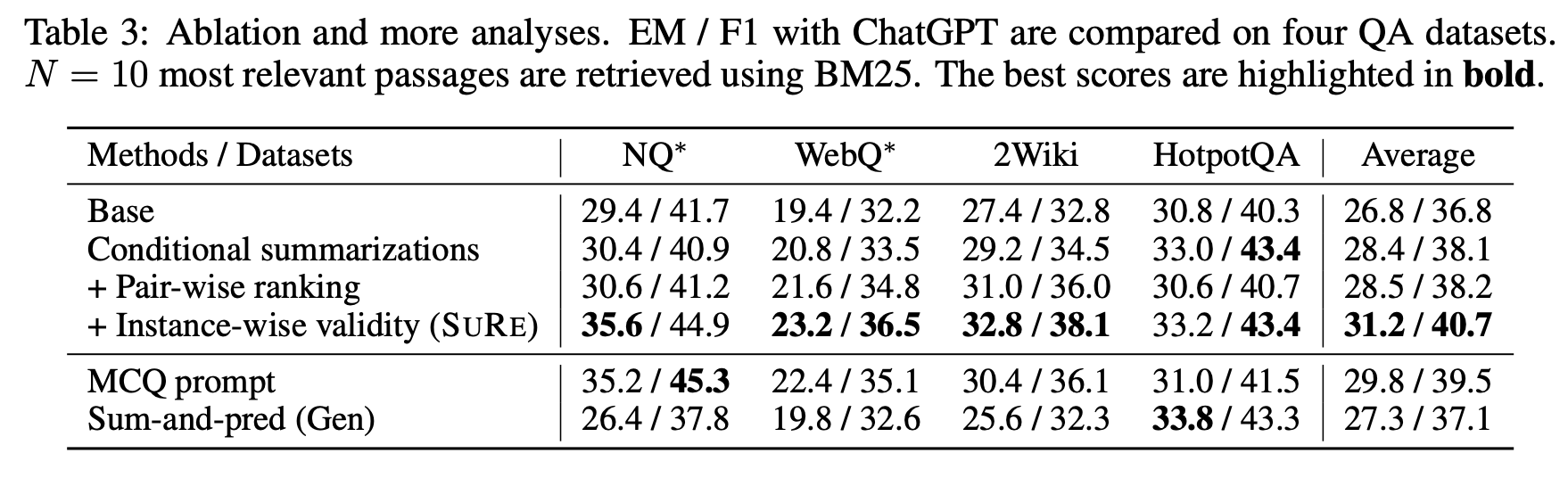
마지막으로, Ablation study를 통해서 각각의 component의 영향을 확인할 수 있습니다. 대체적으로 모든 component가 유의미했지만, 특히 Instance-wise validity부분이 성능 향상에 큰 기여를 했음을 알 수 있습니다.
본 논문에서는 추가적으로 retrieved passages의 갯수인 $N$을 증가시킴에 따라 성능이 개선되었다는 점을 확인했습니다. 이는 후속 연구에서도 참고할 만한 연구 결과라고 생각합니다.

SuRe를 통해서 생성한 Summary가 Generic Summary보다 어떤 부분에서 더 나은지 보여주는 구체적인 예시를 첨부하며 result section을 마무리하겠습니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.