Paper Review - [NIPS 2014] "Sequence to Sequence Learning with Neural Networks" by Sutskever et al., 2014
Conference : (NIPS) Advances in Neural Information Processing Systems 27, 2014
1. Contributions :
본 논문은 기존의 접근 방식을 넘어서는 혁신적인 방법론을 도입하여, 특히 기계 번역과 같은 Application에서 큰 발전을 이루었습니다. 논문이 핵심 내용들을 요약하면 다음과 같습니다.
- 1-1. Sequence 학습을 위한 End-to-End 접근법의 도입
- 이전에는 단어를 벡터로 Embedding하는 것에 큰 중점을 뒀습니다. 이 방식은 단어 단위의 변환에는 유용했지만, Sequence 전체의 문맥을 이해하고 처리하는 데는 한계가 있었습니다.
- 본 논문은 LSTM 네트워크를 활용하여 입력 Sequence를 직접 Target Sequence로 변환하는 새로운 End-to-End 접근 방식을 제안합니다. 이는 중간 단계 없이 전체 Sequence를 처리함으로써, Model이 문맥을 더 잘 이해할 수 있게 합니다.
- 1-2. LSTM 네트워크의 효과적인 활용
- 저자들은 LSTM을 사용하여 입력 Sequence를 고정된 차원의 Vector로 Encoding하고, 그 Vector를 다시 Target Sequence로 Decoding합니다. 이 접근법은 영어에서 프랑스어로의 기계 번역 작업에 적용되어, 높은 BLEU Score(34.8)를 달성했습니다.
- 이 과정을 통해 LSTM이 문장과 구문의 의미를 합리적으로 표현할 수 있음이 증명되었습니다.
- 1-3. 입력 단어 순서의 역전
- 입력 Sequence의 단어 순서를 뒤집는 간단하지만 효과적인 전략을 도입했습니다. 이는 LSTM이 단기 의존성을 더 쉽게 학습할 수 있게 하여, 입력과 출력 사이의 장기 의존성을 효과적으로 처리합니다.
- 이러한 순서 역전은 모델이 더 복잡한 문맥과 문장 구조를 이해하고, 전반적인 번역 품질을 개선하는 데 중요한 역할을 했습니다.
2. Backgrounds :
Sequence 데이터는 단일 단어보다 훨씬 많은 정보를 포함할 수 있으며, 음성 인식이나 기계 번역과 같은 과제를 해결하는 데 있어 매우 중요한 역할을 합니다. 그러나 전통적인 DNN(Deep Neural Network) 모델은 고정된 차원의 벡터로만 정보를 인코딩하는 한계를 가지고 있습니다. 이는 Sequence의 길이가 고정되어 있지 않고 다양할 수 있다는 사실과 맞지 않습니다. Sequence의 길이가 가변적일 수 있기 때문에, 모든 Sequence를 효과적으로 처리하기 위해서는 이러한 차원의 제약을 넘어서는 방법이 필요합니다. 이러한 제약을 뛰어넘은 LSTM에 대해서 먼저 소개하겠습니다.
LSTM은 Vanilla RNN의 Vanishing Gradient 문제를 해결하기 위해 고안된 신경망입니다. Deep Neural Network에서 층이 깊어질수록 발생하는 Vanishing Gradient 문제는 역전파 과정에서 초기 층으로 갈수록 기울기가 점점 작아져, 모델 성능이 저하되는 현상을 말합니다. LSTM은 Forget Gate, Input Gate, Output Gate로 구성되어 이 문제를 효과적으로 해결합니다.
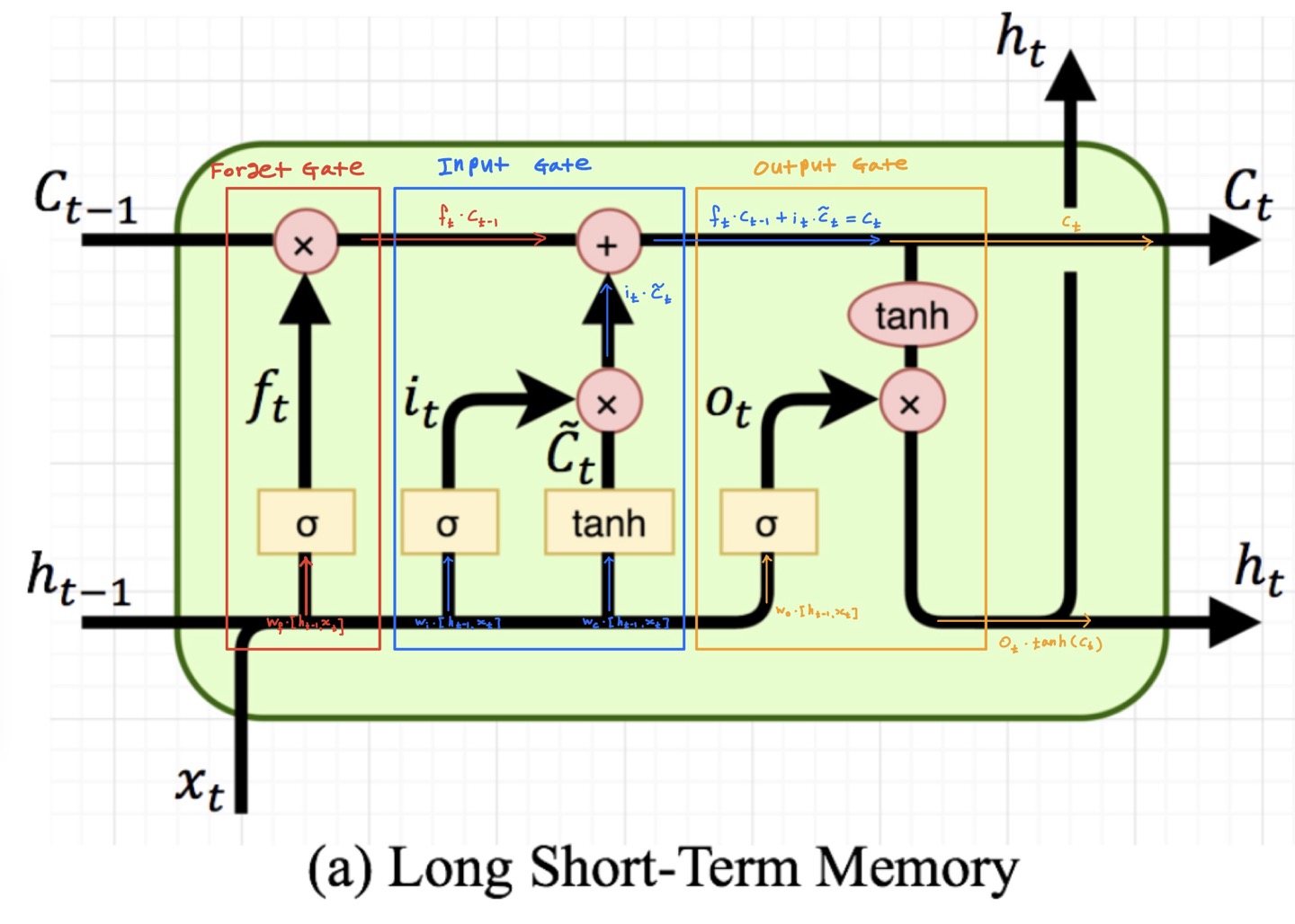
2-1-1. 망각 게이트(Forget Gate)
해당 게이트는 과거 정보를 어느 정도 기억할지를 결정하는 게이트입니다. 과거 정보와 현재의 데이터를 입력받은 이후, $\sigma(\cdot)$을 거친 결과 값이 0에 가까울 수록 과거의 정보는 줄어들고, 1에 가까우면 과거의 정보를 많이 보존하는 방식으로 작동합니다. 아래의 수식에서 $\sigma(\cdot)$를 거친 0~1의 값이 일종의 가중치로 역할을 하여 과거 정보($c_{t-1}$)에 곱해져 과거정보를 어느 정도 비율로 남길 지를 결정하게 됩니다.
\[f_{t} = \sigma(w_{f}\cdot[h_{t-1}, x_{t}] + b_{f})\] \[c_{t} = f_{t} \cdot c_{t-1}\]- $f_t$ : 현재 시점에서 어떤 정보를 버릴지 결정하는 망각 게이트의 출력
- $\sigma(\cdot)$ : 시그모이드 함수
- $w_f, b_f$ : 망각 게이트의 가중치와 편향
- $h_{t-1}$ : 이전 상태
- $x_t$ : 현재 입력
2-1-2. 입력 게이트(Input Gate)
입력 게이트는 현재 정보를 기억하기 위한 게이트입니다. 과거 정보와 현재 데이터를 입력받아 $\sigma(\cdot)$와 $\tanh(\cdot)$함수를 기반으로 현재 정보에 대한 보존량을 결정합니다. $\sigma(\cdot)$를 거친 결과 값이 0에 가까울 수록 현재의 정보는 줄어들고, 1에 가까우면 현재의 정보를 많이 보존하는 방식으로 작동합니다. 또한, $\tanh(\cdot)$를 거치면서 $t$시점에서 새로운 셀의 값을 -1~1 사이로 조정하게 됩니다. 이는 새로운 셀의 값이 너무 크거나 작아지는 것을 방지해 학습의 안정성에 기여한다고 합니다. 또한, 비선형성을 추가해 모델이 더 복잡한 패턴과 의존성을 학습할 수 있게 해줍니다.
\[i_{t} = \sigma(w_{i}\cdot[h_{t-1}, x_{t}] + b_{i})\] \[\tilde{c_{t}} =\tanh(w_{c}\cdot[h_{t-1}, x_{t}]+b_{c})\] \[c_{t} = c_{t-1 } + i_{t} \cdot \tilde{c_{t}}\]- $i_t$ : 현재 시점에서 어떤 정보를 추가할지 결정하는 입력 게이트의 출력
- $\tilde{c}_t$ : 새로운 후보 값으로, 모델이 새로운 입력을 받을 때마다 현재 상태와 어떻게 상호작용할지에 대한 잠재적인 방향을 제시합니다.
2-1-3. 출력 게이트(Output Gate)
LSTM의 출력 게이트는 과거 정보와 현재 입력을 종합하여 뉴런의 출력 여부를 결정합니다. 이 과정에서 hidden state($h_{t-1}$)와 현재 시점의 입력($x_{t}$)이 다음 hidden state($h_{t}$)의 계산에 사용됩니다. 출력 게이트는 이 hidden state를 활용하여, 그 시점의 출력을 결정하게 됩니다. 계산 결과가 1에 가까우면, 해당 정보는 중요하게 간주되며 최종 출력으로 전달됩니다. 반면, 0에 가까우면 해당 정보는 무시됩니다. 이 메커니즘을 통해 LSTM은 중요한 정보만을 선택적으로 전달하면서 Sequence data의 장기 의존성을 효과적으로 학습할 수 있습니다.
\[o_{t} = \sigma(w_{o}\cdot[h_{t-1}, x_{t}])\] \[h_t = o_t \ast \tanh(c_t)\]- $o_t$ : 현재 시점에서 어떤 정보를 출력할지 결정하는 출력 게이트의 출력
- $c_t$ : 현재 시점의 cell 상태
- $h_t$: 현재 시점의 hidden 상태
2-1-4. Cell State Update
cell state는 이전 cell state와 새로운 정보가 결합된 결과입니다.
\[c_t = f_t \ast c_{t-1} + i_t \ast \tilde{c}_t\]- $c_t$ : 현재 시점의 cell 상태
- $\ast$ : Element-wise Product
2-1-5. Hidden State의 역할
- LSTM에서 hidden state는 Sequence 데이터의 현재까지의 정보를 요약하여 저장하고, 이를 다음 레이어나 Sequence의 다음 단계로 전달합니다. 이를 통해 Sequence의 시간적 의존성을 모델링하고, 모델의 의사결정 및 예측에 필요한 정보를 제공합니다. hidden state는 중요한 정보의 선택적 활용을 가능하게 하여, LSTM이 다양한 Sequence 모델링 작업에서 뛰어난 성능을 발휘할 수 있도록 합니다.
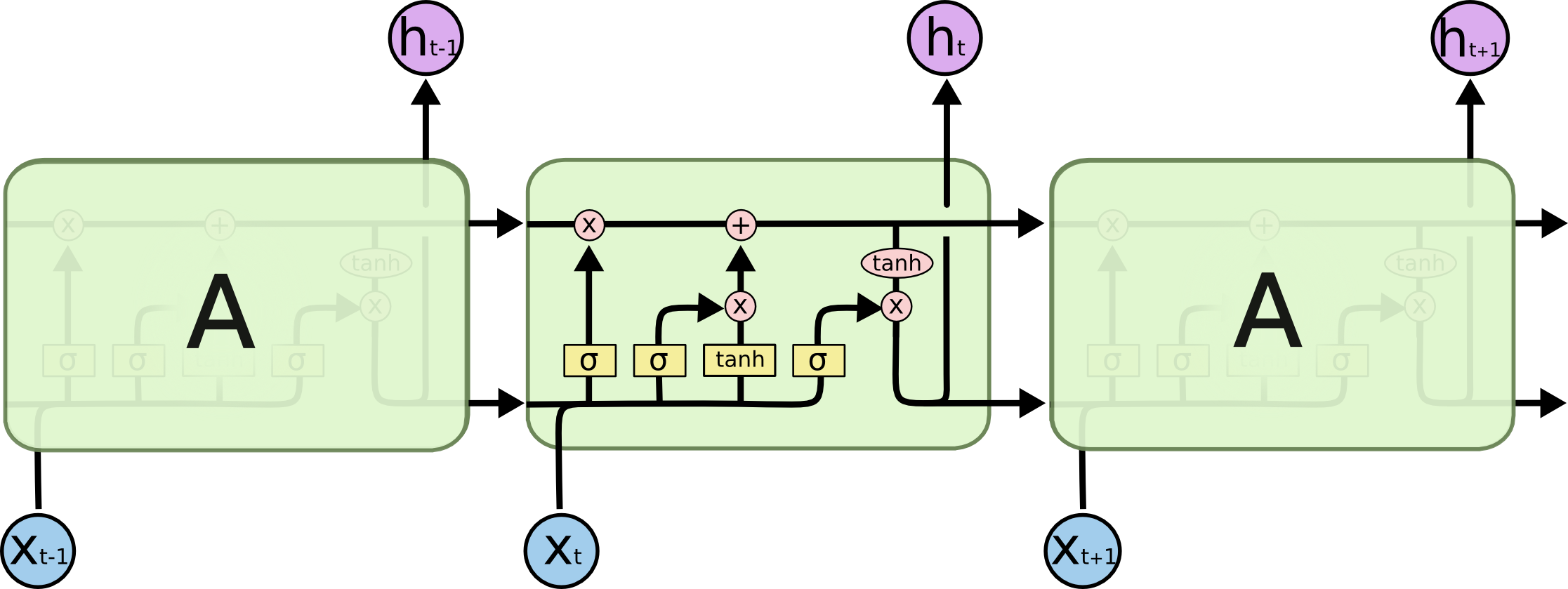 이미지와 같이 LSTM은 위와 같은 구조로 Sequence data를 처리하게 됩니다.
이미지와 같이 LSTM은 위와 같은 구조로 Sequence data를 처리하게 됩니다.
SMT는 대량의 텍스트 데이터를 분석하여 한 언어를 다른 언어로 자동으로 번역하는 방법 중 하나입니다. 생각해보면, 어떤 문장을 번역할 때, 우리는 가능한 번역들 중에서 가장 자연스럽고 정확한 것을 선택합니다. SMT도 비슷한 방식으로 작동합니다. 이는 두 가지 주요 요소를 사용합니다:
- 번역 가능성: ‘사과’라는 단어가 영어에서 프랑스어로 ‘pomme’으로 번역될 확률은 얼마나 될지 계산하여 확률이 높은 것을 선정합니다.
- 언어 모델: ‘I eat apple’을 프랑스어로 번역할 때, ‘Je mange pomme’과 ‘Je pomme mange’ 중 어느 것이 더 자연스러운지 평가하여 번역에 반영합니다.
SMT는 이 두 요소를 결합하여 가장 자연스러우면서도 정확한 번역을 생성합니다. 이에 대한 구체적인 방법론은 Skip하겠습니다.
Perplexity는 언어 모델이 얼마나 잘 작동하는지를 측정하는 지표입니다. 언어 모델이란, 다음에 올 단어를 예측하는 컴퓨터 프로그램입니다. 예를 들어, “I eat” 다음에 무슨 단어가 올지 컴퓨터가 예측합니다. Perplexity는 컴퓨터가 예측에 ‘당황’하는 정도를 나타냅니다. 숫자가 낮을수록 모델이 단어를 더 잘 예측한다는 것을 의미합니다. 수식으로는 다음과 같이 표현할 수 있습니다:
\[\text{PPL}= P(w_1,w_2,w_3,\ldots, w_N)^{-\frac{1}{N}} = (P(w_1)\prod_{i=2}^N P(w_i | w_1,w_2,\ldots,w_{i-1}))^{-\frac{1}{N}}\]- $N$ : 문장에서 Token의 개수
- $P(w_1,w_2,w_3,\ldots, w_N)$ = 정답 문장에 대한 확률
PPL을 쉽게 표현하자면, $N=3, P=\frac{1}{10}$이면 사실상 모델이 “A 아니면, B아니면, C아니면, D아니면, …J 인데 정확히는 모르겠다.” 라고 하는 것과 비슷합니다. 즉 모델이 정답에 확신이 없는 상태를 의미합니다. 따라서, 이 값이 낮을수록, 모델이 데이터를 더 정확하게 예측하고 있음을 의미합니다.
일반적으로 번역에 있어서 PPL보다는 BLEU Score가 더욱 신뢰성이 있는 지표로 평가됩니다. BLEU는 0과 1 사이의 값이 나오게 되는데 그 값이 클수록 좋은 성능을 가진다고 평가합니다. 수식을 통해서 Score에 어떤 의미들이 담겨있는지 살펴보겠습니다.
\[\text{BLEU} = \text{BP} \cdot \prod_{n=1}^N P_{n}^{w_n}\]- $p_n$ : n-gram precision
- $w_{n}$ : weights
- $\text{BP}$ : Brevity penalty - 출력이 짧을 때에 Penalty를 부과해줍니다.
$N$ : Default가 4로 설정됩니다.
먼저, n-gram precision에 대해서 살펴보겠습니다. n-gram precision은 연속한 n개 단어가 정답 문장에 존재하는지 여부로 계산합니다.
Target : 나는 Seq2Seq 논문을 리뷰하면서 Seq2Seq 모델의 성능을 평가하는 지표를 소개한다.
Prediction : 나는 Seq2Seq 논문을 읽고, Seq2Seq 논문을 리뷰하고 Seq2Seq 모델의 성능 지표를 소개한다.
위의 예시로 3-gram precision까지 측정해보겠습니다. n-gram Precision을 측정할 때 유의할 점은, 위의 예시에서 Prediction에는 ‘Seq2Seq’가 3개이지만, Target에는 2개가 있습니다. 이런 경우에 n-gram precision의 분자에 ‘Seq2Seq’에 대해서는 2개만 반영됩니다.
1-gram의 경우 분모에 총 12개의 1-gram이 있다는 것이 들어가고, 분자에는 ‘나는’ 1개, ‘Seq2Seq’ 2개, ‘논문을’ 1개, ‘모델의’ 1개, ‘지표를’ 1개, ‘소개한다’ 1개로 분자에 7이 들어갑니다.
1-gram의 경우 분모에 총 11개의 2-gram이 있다는 것이 들어가고, 분자에는 ‘나는 Seq2Seq’ 1개, ‘Seq2Seq 논문을’ 1개, ‘Seq2Seq 모델의’ 1개, ‘지표를 소개한다’ 1개로 분자에 4가 들어갑니다.
이제 감이 오셨으리라 생각합니다. $N=3$으로 가정하고 $\prod_{n=1}^N P_{n}^{w_n}$을 구해보겠습니다.
1-gram precision : $\frac{\text{Target과 Prediction에 동시에 있는 1-gram 개수}}{\text{Prediction에서 1-gram 개수}} = \frac{7}{12}$
2-gram precision : $\frac{\text{Target과 Prediction에 동시에 있는 2-gram 개수}}{\text{Prediction에서 2-gram 개수}} = \frac{4}{11}$
3-gram precision : $\frac{\text{Target과 Prediction에 동시에 있는 3-gram 개수}}{\text{Prediction에서 3-gram 개수}} = \frac{1}{10}$
위에서 처럼 n-gram을 쓰는 이유는 1-gram만 쓴다면 ‘나는 읽고 논문을 Seq2Seq’와 같이 순서만 바뀐 것에 대해서도 좋은 평가를 하게 되기 때문에, 순서를 고려해주기 위함이라고 볼 수 있습니다.
Target : 나는 Seq2Seq 논문을 리뷰하면서 Seq2Seq 모델의 성능을 평가하는 지표를 소개한다.
Prediction : 나는 Seq2Seq 논문을 소개한다.
위의 예시와 같이 번역을 하게 된다면, 중요한 정보가 많이 생략되어 번역을 잘 했다고 평가하기 어렵게 됩니다. 그럼에도 n-gram precision이 높은 값을 가질 수 있게 되어서, 이러한 부분에 대해 Penalty를 가해줍니다. 수식은 다음과 같습니다.
\[\text{BP} = \begin{cases} 1&\text{if } c\geq r \\ e^{(1-r/c)} & \text{if } c<r \end{cases}\]- ${r}$ : Reference(정답) 문장 길이
- ${c}$ : Candidate(예측) 문장 길이
최종적으로 BLEU Score는 위에서 구한 값에 100을 곱해준 형태로 위의 예시에서는 27.68이($\text{BP} = 1$) 나오게 됩니다.
Background에서 살펴보았듯이. LSTM은 Vanishing Gradient로 인해 발생하는 Long Term Dependency(Sequence 내에서 멀리 떨어진 요소들 사이의 관계를 학습하는 데 어려움을 겪는 현상)를 해결하였습니다. 또한, Sequence내에서 ‘
본 논문에서는 WMT’14 English to French Machine Translation task에 LSTM을 기반으로한 모델을 학습시켰지만, 몇 가지 중요한 방법들이 적용되었습니다.
입력 시퀀스와 출력 시퀀스를 처리하기 위해 서로 다른 두 개의 LSTM을 사용했습니다. 이 방식은 모델의 파라미터 수를 적은 계산 비용으로 증가시켜, 여러 언어 쌍을 동시에 학습하는 것을 자연스럽게 만들었습니다.
깊은 구조의 LSTM을 사용하여, 얕은 구조 대비 뛰어난 성능을 달성했습니다. 네 층으로 구성된 LSTM은 모델의 학습 능력과 복잡성을 크게 향상시켰습니다.
입력 문장의 단어 순서를 뒤집음으로써, 모델이 입력과 출력 사이의 Long term dependency을 더 효과적으로 학습할 수 있게 했습니다. 예를 들어, 문장 ‘a, b, c’를 ‘α, β, γ’로 Mapping하는 대신, ‘c, b, a’를 ‘α, β, γ’로 매핑하도록 LSTM을 구성했습니다. 이러한 순서 뒤집기는 특히 입력의 시작 부분과 출력의 시작 부분이 서로 가까워지게 함으로써, 모델이 두 Sequence 사이의 관계를 더 쉽게 학습할 수 있도록 합니다. 이는 SGD(Stochastic Gradient Descent)가 입력과 출력 사이의 Communication을 쉽게 설정할 수 있게 하여, 전반적인 모델 성능을 크게 향상시키는 간단하면서도 효과적인 데이터 전처리 방법으로 나타났습니다.
3-4. Decoding and Rescoring
- 주어진 소스 문장 $S$로부터 정확한 번역 $T$의 로그 확률 $\log{P(T|S)}$을 최대화하는 것입니다. 이는 모든 훈련 데이터셋 내 문장 쌍에 대해 로그 확률의 합을 최대화함으로써 달성됩니다.
- Beam Search : 훈련 완료 후, LSTM을 사용해 가장 가능성 높은 번역을 생성합니다. 이는 Beam Search Decoder를 활용하여 수행되며, Decoder는 각 Time step에서 모든 가능한 단어로 확장된 부분 가설들을 유지합니다. “End Of Sentence” (EOS)가 가설에 추가되면, 완성된 가설로 간주되어 Beam에서 제거됩니다. Beam의 크기는 성능에 큰 영향을 미치며, Beam의 크기가 1일 때도 모델은 잘 작동하며, 크기가 2일 때 성능이 좋았다고 합니다.
- Rescoring : LSTM은 1000개의 번역 리스트를 Rescoring하는 데도 사용되었습니다.. 이는 각 가설의 로그 확률을 계산하고, 이를 기존 점수와 평균을 내어 최종 점수를 부여하는 방식으로 이루어집니다.
특히 3-3의 입력 Sequence의 순서를 뒤집는 과정을 일종의 Data Augmentation이라고 생각합니다. 논문에서 모델이 Powerful한 성능을 내는 것에 큰 기여를 한 것이 3-3인 만큼 Data를 잘 정제하여 모델에 넣는 것은 중요한 과정이라는 것을 확인할 수 있었습니다.
4. Empirical Results
논문에서의 결과로 BLEU Score를 살펴보았을 때, LSTM이 좋은 Performance를 내었음을 확인할 수 있습니다. 논문에서는 특히 Sequence의 순서를 뒤집는 과정이 성능 향상에 큰 기여를 했다고 주장합니다.

또한, Sequence들을 Embedding한 결과 서로 비슷한 의미를 가지는 Sequence들이 비슷한 위치에 Embedding되는 것을 확인할 수 있었습니다. 이는 Model이 Sequence에서 단어들의 순서가 바뀜에도 의미를 공유하면 비슷한 Sequence라는 것을 잡아내었다는 것을 보여줍니다.
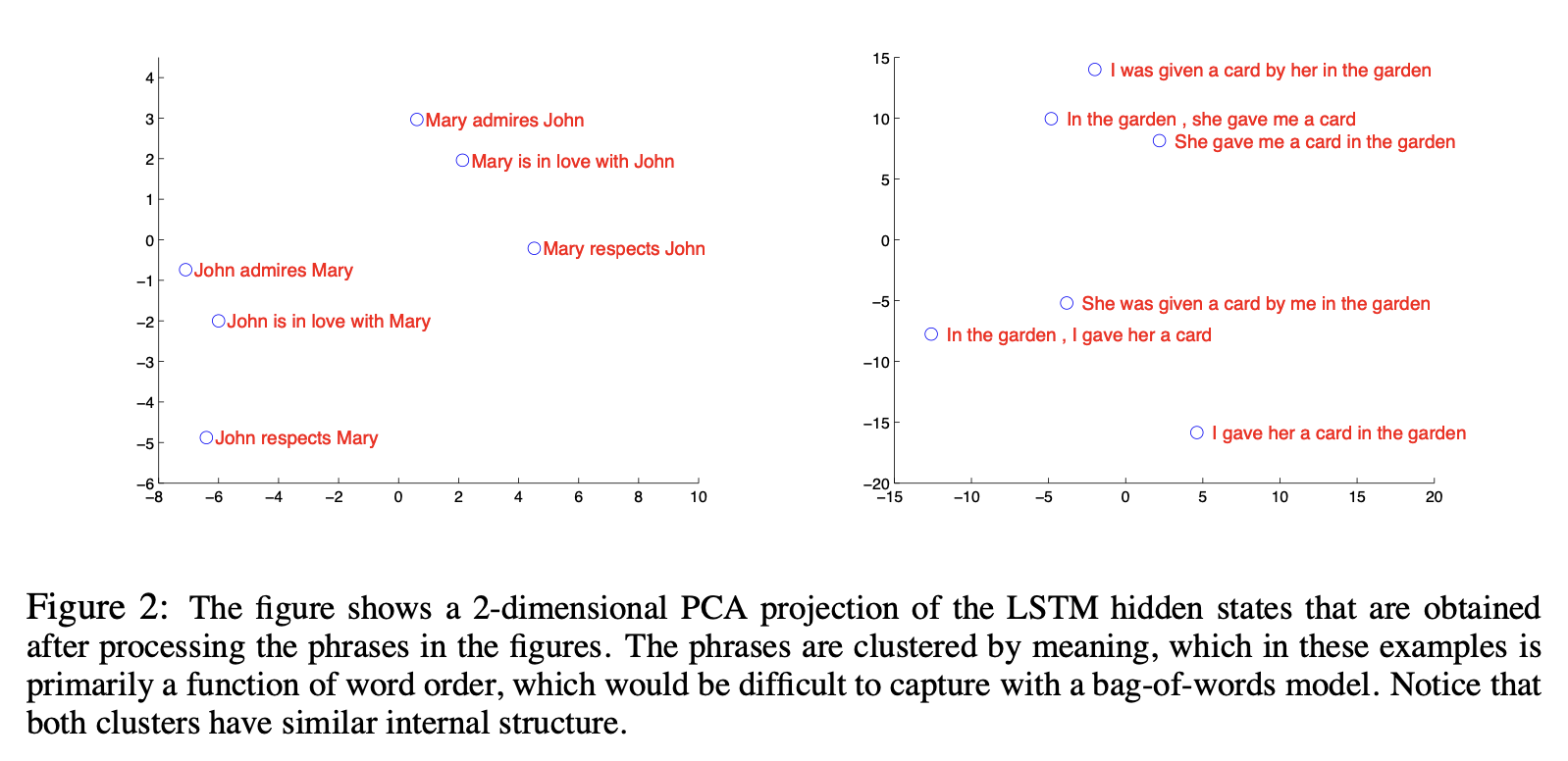
결과적으로 본 논문에서는 LSTM을 활용하여 긴 문장을 정확하게 번역할 수 있게 되었다고 하며, SMT보다 성능이 우수하다고 합니다. 또한, Sequence에서 단어의 순서를 뒤집는 것이 Model의 성능을 개선했다는 점에 대해서 놀라움을 표현했습니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.