Paper Review - [ICLR 2024] "Self-RAG ; Learning To Retrieve, Generate, and Critique Through Self-Reflection", Akari Asai et al., Oct 2023
Conference : ICLR (The International Conference on Learning Representations), 2024
1. Contributions
RAG(Retriever Augmented Generation)은 Query에 대응하는 문서를 검색하여 얻은 non-parametric knowledge를 바탕으로 LLM의 parametric knowledge와 결합하여 답변을 생성함으로써 기존 LLM의 한계를 극복하려 합니다. 이 방법은 특히 지식 기반의 질문(Knowledge-intensive task)에 대한 답변 생성에서 효과적이라고 알려져 있습니다. 그러나 이 과정에서 retriever가 질의와 관련성이 낮은 문서들을 검색해오면, 오히려 LLM이 정확하고 신뢰할 수 있는 답변을 생성하는 데 방해가 될 수 있습니다. 즉, 검색된 문서의 품질이 답변의 질을 결정짓는 중요한 요소가 됩니다.
이러한 문제점을 해결하기 위해, 본 논문에서는 Self-Reflective Retrieval-Augmented Generation (Self-RAG) 기법을 제안합니다. Self-RAG는 기존의 RAG Framework를 발전시킨 모델로, 검색된 문서(passage)들이 질의에 대한 답변 생성에 있어 적절한지를 스스로 평가하는 기능을 추가했습니다. 이를 위해 모델은 검색된 passage들을 분석하고, 각 passage의 적합성을 평가하는 반성 토큰(reflection token)을 생성하여, 모델 스스로가 자기 성찰을 진행합니다. 이 반성 토큰은 모델이 검색된 passage의 질을 스스로 평가하고, 그 중에서도 가장 적합한 passage만을 선택하여 답변 생성에 활용하도록 돕습니다. 결과적으로, Self-RAG는 불필요하거나 관련성이 낮은 정보로 인한 혼란을 줄이고, 답변의 정확성과 관련성을 향상시키는 데 기여합니다.
Self-RAG의 도입은 RAG의 성능을 한 단계 더 발전시키는 중요한 진전이 되었습니다. 이는 LLM이 외부 지식을 활용하는 방식을 더욱 효율적이고 지능적으로 만들어, 다양한 유형의 질의에 대한 보다 정확하고 신뢰할 수 있는 답변을 생성할 수 있도록 합니다. 또한, 이러한 접근 방식은 model의 Self-reflection 및 Self-assessment 능력을 강화하여, model의 자율성과 적응성을 높이는 데에도 기여할 수 있습니다.
2. Backgrounds
2-1. Special tokens in Self-RAG
Self-RAG는 크게 두 종류의 Special token, 즉 반성 토큰(reflection token)을 사용하여 작동합니다. Reflection token은 검색 토큰(retrieval token)과 비평 토큰(critique token)으로 나뉩니다.
Retrieval token은 query에 대해 외부 문서를 검색할 필요가 있는지 여부에 대한 정보를 담고 있습니다. 만약 검색을 통해 얻은 정보가 답변 생성에 유용하다고 판단될 경우, model은 retrieval token을 생성합니다. 반대로, 검색이 필요하지 않다고 판단되면 retrieval token을 생성하지 않습니다.
Critique token은 각각의 생성된 답변의 quality에 관한 정보를 담고 있습니다. 여기서 생성된 답변은 query $q$와 k개의 passages $[d_1, d_2, \ldots, d_k]$ 를 하나씩 묶어서 생성됩니다.
즉 $\bar{a}_1 = \text{LLM}(q, d_1), \bar{a}_2 = \text{LLM}(q, d_2), \ldots$과 같이 생성됩니다.
Model은 검색된 각 passage와 query의 관련성을 평가하고, 이를 바탕으로 생성된 답변($\bar{a}_i$)가 얼마나 유용한지를 판단합니다. 이 과정에서 critique token을 사용하여 품질이 가장 좋은 답변을 선택하도록 합니다.
이렇게 Self-RAG는 retrieving과 critizing의 두 단계를 거쳐, 더 정확하고 유용한 답변을 생성할 수 있도록 설계되었습니다. 이는 model이 단순히 정보를 검색하는 것을 넘어, 검색된 정보의 질과 생성된 답변의 유용성을 스스로 평가하고 최적의 답변을 선택할 수 있게 만듭니다.
2-2. RLHF(Reinforcement Learning from Human Feedback)
RLHF(Reinforcement Learning from Human Feedback)는 ML에서 모델의 성능을 향상시키는 방법 중 하나입니다. 이 방법은 주로 NLP 작업에 적용되어, model이 생성한 텍스트의 품질을 인간의 feedback을 통해 개선합니다.
RLHF는 크게 세 단계로 이루어집니다: 사전학습(pre-training), 보상모델링(reward modeling), 그리고 강화학습(reinforcement learning).
- 사전학습(Pre-training): 대규모 dataset을 사용하여 model의 초기 버전을 학습시킵니다. 이 단계에서 model은 언어의 기본 구조와 패턴을 학습하여, 문장을 생성하는 기본 능력을 개발합니다.
- 보상모델링(Reward Modeling): 인간 평가자가 model이 생성한 텍스트를 평가하고, 그 품질에 대한 feedback을 제공합니다. 이 feedback은 보상모델을 학습시키는 데 사용되어, 생성된 텍스트의 품질을 수치적으로 평가할 수 있는 기준을 마련합니다. 보상모델은 생성된 텍스트가 인간의 선호도나 요구사항을 얼마나 잘 충족시키는지를 평가하는 역할을 합니다.
- 강화학습(Reinforcement Learning): 보상모델의 평가를 바탕으로, model은 보다 높은 보상을 받을 수 있는 방향으로 자신의 행동(텍스트 생성 방식)을 조정합니다. 이 과정을 통해 model은 인간의 평가 기준에 맞는 더 나은 텍스트를 생성하는 방법을 학습합니다.
RLHF는 특히 생성 모델의 출력이 인간의 언어적 직관과 일치하도록 만드는 데 유용합니다. 예를 들어, 대화 모델이 더 자연스럽고 유용한 대화를 생성하거나, 기계 번역 model이 더 정확하고 자연스러운 번역을 생성하도록 개선하는 데 사용될 수 있습니다. RLHF를 통해 model은 단순히 데이터에서 패턴을 학습하는 것을 넘어, 인간의 질적 판단 기준을 내면화하고 이를 반영한 결과물을 생성할 수 있게 됩니다.
3. Methodology
3-1. Problem Formalization and Overview
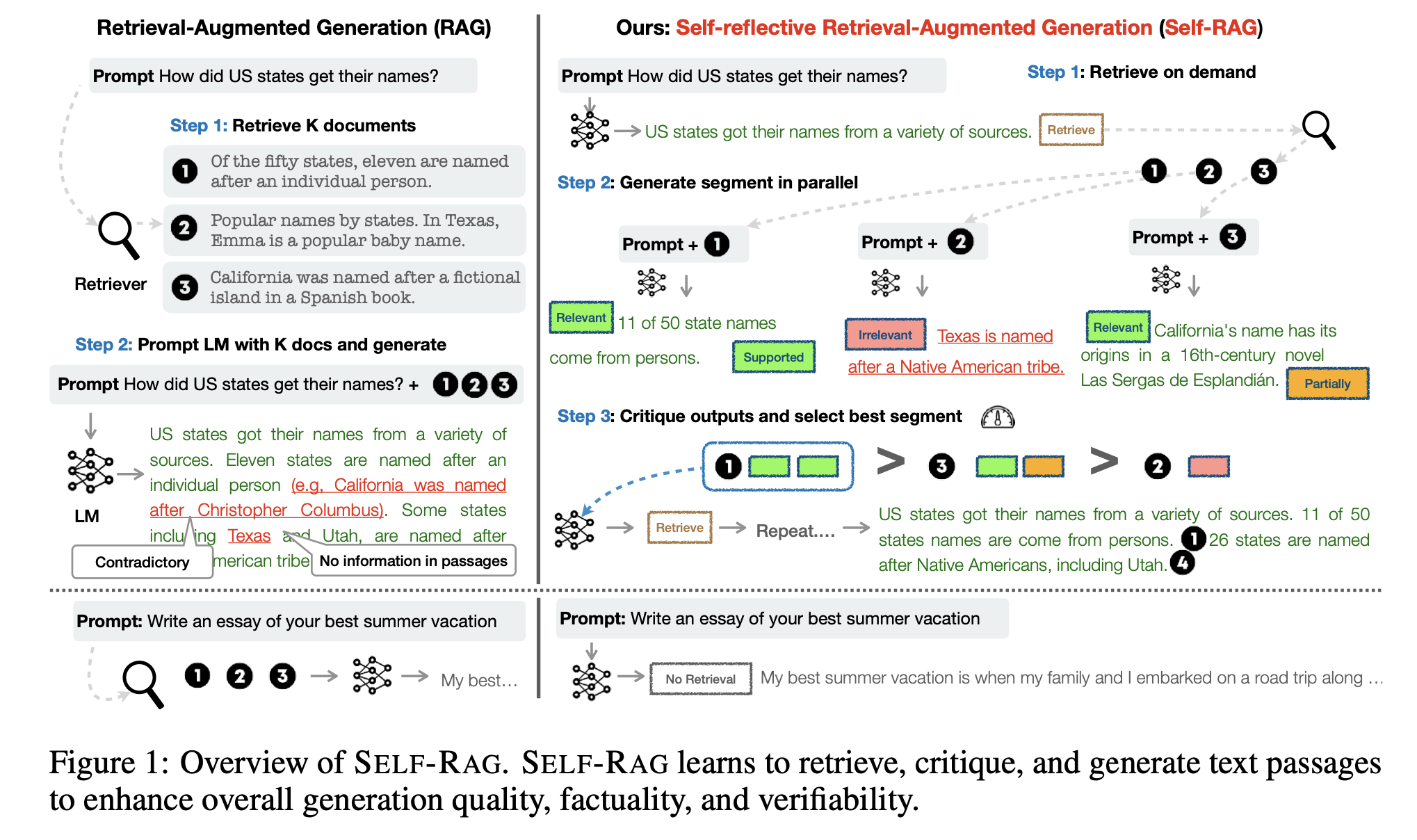
본 논문에서 Model $M$을 통해 sequential output $y = [y_1, \ldots, y_T]$를 생성할 때, 각각의 $y_t$에 t번째 segment에 대한 generated token과 reflection token, critique token을 포함시키는 방식으로 생성하게 됩니다. 여기서 중요한 점은 $y_t$는 document로 부터 추출한 passage 자체가 아니라, 이를 활용하여 새로운 텍스트를 생성했다는 점입니다. 즉, 사용자의 query에 대한 답을 passage를 통해서 새롭게 $y_t$를 생성해낸 다음에, 생성된 $y_t$에 대해 self-reflection을 하여 special tokens를 생성한다는 것입니다. Special tokens을 어떻게 생성하고 활용하는지에 대한 표를 살펴보겠습니다.

먼저, ‘Retrieve’ token은 Retriever를 통해 document로 부터 retrieving을 할지에 대해서 결정해주는 token입니다. ‘IsREL’ token은 추출한 Document가 relevant한지 irrelevant한지 판단할 수 있도록 해주는 token입니다. ‘IsSUP’ token은 추출한 Document가 전적으로 도움이 되는지, 일부만 도움이 되는지, 도움이 되지 않는지 판단할 수 있도록 해주는 token입니다. 마지막으로, ‘IsUSE’는 query와 generated answer를 input으로 하여, generated answer가 도움이 얼마나 되었는지를 수치적으로 보여주는 token입니다. IsREL, IsSUP, IsUSE는 Critique token으로 역할을 합니다. 이제 위의 token들을 어떻게 활용하는지 Algorithm을 통해 살펴보겠습니다.

먼저, Language Model $M$과 Retriever $R$ 그리고 passage collections ${{d_1, \ldots, d_N}}$을 토대로 algorithm이 작동됩니다. 또한, Input으로 prompt $x$와 지금까지 생성된 모든 generation $y_{<t}$를 넣어주면, $y_t$를 생성하게 됩니다.
먼저 pretrained model $M$을 통해서 Retrieve token의 output {yes, no, continue}를 생성하고, yes가 output인 경우 Passages set $D$에서 query $x$와 직전 시점 output $y_{t-1}$을 통해 relevant passage $d$를 추출합니다. 이후에 query $x$, relevant passage $d$와 $y_{t}$, $y_{<t}$를 통해 ‘IsREL’ token {relevant, irrelevant}를 생성하고, 각각의 $d$와 $x, y_t$를 통해 ‘IsSUP’ token {fully supported, partially supported, no support}과 ‘IsUSE’ token {5,4,3,2,1}을 생성합니다. 마지막으로 ‘IsREL’, ‘IsSUP’, ‘IsUSE’ token을 토대로 $y_t$의 rank를 결정하게 됩니다.
Pretrained model $M$의 결과로 Retrieve token이 ‘No’가 생성되면, 다른 generate model $M_{gen}$을 통해서 $y_t$를 예측하고 query $x$와 $y_t$를 토대로 ‘IsUSE’ token {5,4,3,2,1}을 예측하게 됩니다.
3-2. Self-RAG Training
본 논문에서는 supervised learning을 통해서 critic model $C$와 generator model $M$을 학습시켰습니다.
- 3-2-1 Training the Critic Model
먼저 critic model을 학습시키기 위해서 본 논문에서는 GPT-4를 활용하여 generated answer에 대한 feedback을 위한 special token을 생성했습니다. 그러나, GPT-4같은 model은 API Cost가 높다는 한계가 있어, 비용 절감을 위해 knowledge distillation을 활용했습니다. 일정 비용을 지불하는 GPT-4 API를 통해서 한차례 generated answer $X$에 대응되는 reflection tokens $Y$를 생성한 다음에, ${{X^{\text{sample}}, Y^{\text{sample}}}}$ ~${{X, Y}}$을 통해 sample을 무작위로 뽑아 critic model을 학습시킵니다. 결과적으로, GPT-4가 teacher model로 역할을 하며, critic model이 student model이 되어, critic model이 GPT-4의 reflection token을 생성하는 능력을 모방하도록 학습이 됩니다. 이러한 학습 방식은 연구의 재현성을 높이며, 비용적은 측면에서 효율적일 수 있도록 합니다. 구체적인 방식은 아래 사진과 같습니다.
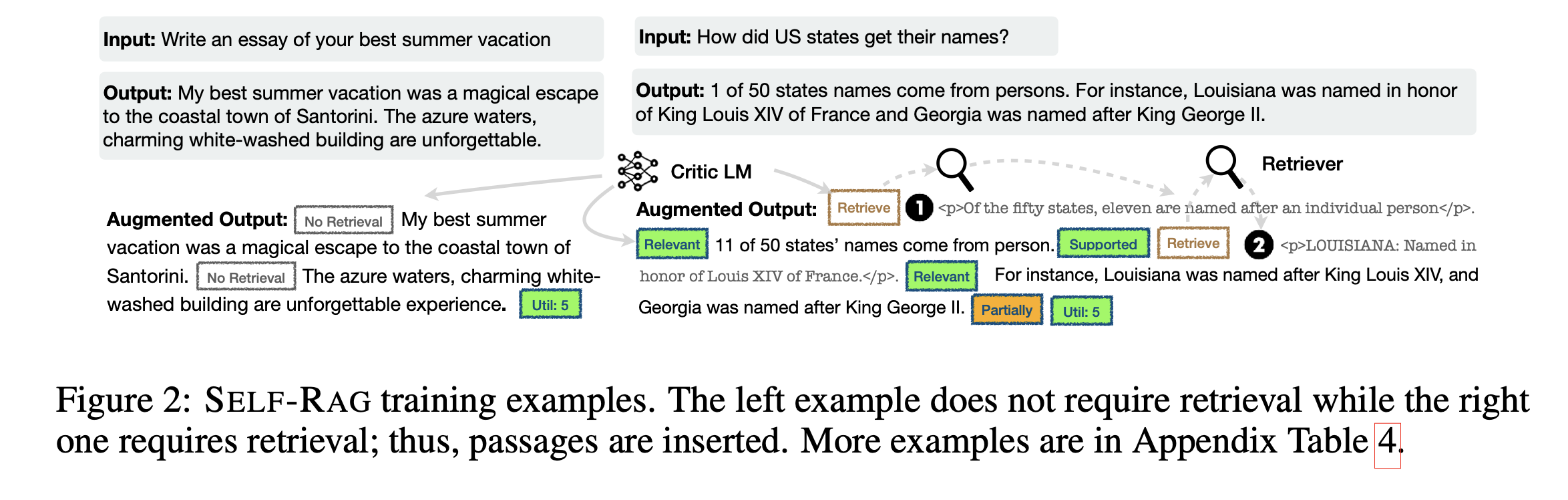
논문에서는 GPT-4를 활용하여 각 type별로 4k~20k에 이르르는 supervised training data $D_{critic}$을 만들었다고 합니다. 학습시킬 때의 수식은 다음과 같습니다.
\[\max_{c} \mathbb{E}_{((x,y),r) \sim D_{\text{critic}}} \log p_{C}(r | x, y), \quad r \text{ }\text{ } \text{for reflection tokens}\]$x$ : Input query
$y$ : Generated answer
$r$ : Reflection token
Input query $x$와 generated answer $y$를 토대로 reflection token $r$을 잘 생성할 수 있도록 하는 수식임을 쉽게 확인할 수 있습니다.
- 3-2-2 Training the Generator Model
Generator Model을 학습시킬 supervised dataset을 만들기 위해 주어진 input-output pair $(x,y)$에서 original output $y$를 retrieval과 critic model을 활용하여, $y$에 special token을 추가해주는 augmentation을 해줍니다. 과정은 다음과 같습니다.
먼저, 각각의 segment $y_t \in y$에 대해 critic model $C$을 활용하여 ‘retrieval token을 생성합니다. 이 때, retrieval token = Yes 일 때, Retriever $R$은 top-k passages $\in D$ 를 추출합니다. 각각의 passage에 대해서 다시 cirtic model $C$를 통해 ‘IsREL’ token을 생성하고, relevant하다면 ‘IsSUP’ token을 생성합니다. 그 다음에 retrieved passage나 generated answer에 ‘IsREL’과 ‘IsSUP’ token을 추가해줍니다. 끝으로는, critic model $C$가 전반적인 유용성을 판단하여, ‘IsUSE’ token을 생성하게 됩니다.
위와 같은 방식으로 supervised dataset $D_{gen}$을 만들어준 다음에 아래의 수식에 따라 Generator model을 학습하게 됩니다.
\[\max_{M} \mathbb{E}_{(x,y,r) \sim D_{\text{gen}}} \log p_{M}(y, r | x)\]critic model $C$에서와 달리, generator model $M$은 input query $x$를 토대로 target output $y$와 reflection tokens $r$을 예측하게 됩니다.
3-3. Self-RAG Inference
위에서의 방법들로 reflection tokens를 만듦으로 Self-RAG가 추론 과정에서 각각의 task requirement에 적절하도록 행동하도록 하는 controllable을 달성할 수 있다고 합니다. 예를 들어, Factual accuracy를 요구하는 task에는 retriever가 passage를 더욱 자주 retrieving하도록 하고, 개인의 자서전과 같은 open-ended task에 대해서는 retrieving을 덜 하고 utility score에 우선순위를 두도록 합니다.
마지막으로 Self-RAG가 Inference를 하는 전체적인 흐름을 살펴보겠습니다.
- Tree-decoding with critique tokens
각각의 segment step t 에서 retriever가 필요하다면, Retriever $R$은 K개의 passage를 추출하고, generator $M$은 각각의 passage를 통해 K개의 다른 continuation candidates를 생성합니다. 이후에 segment 단위의 beam search(beam size = B)를 통해 top-B segment continuation을 각각의 time step t에서 생성하고 ,가장 좋은 sequence를 반환합니다.
또한 각각의 segment $y_t$의 score는 아래와 같은 방식으로 매겨지게 됩니다.
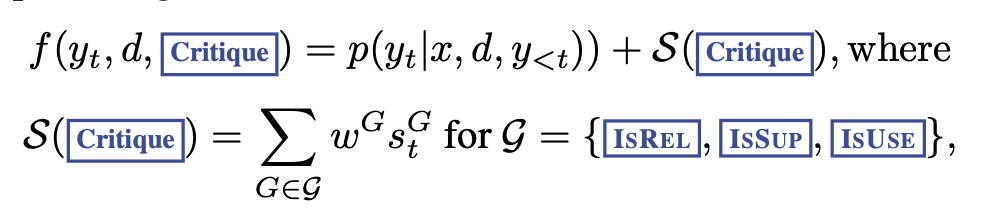
결과적으로, 각 segment $y_t$는 다음과 같은 요소들을 기반으로 점수가 매겨집니다:
- Passage Retrieval: 선택된 passage의 태스크 관련성과 유용성.
- Critique Tokens: 생성된 텍스트가 태스크 요구 사항(예: 정확성, 명확성, 창의성 등)을 어떻게 충족시키는지 평가하는 데 사용되는 토큰.
- Utility Score: 검색 결과와 생성된 텍스트의 전반적인 유용성 평가.
이 과정을 통해, Self-RAG는 주어진 태스크에 맞는 가장 적합하고 질 높은 출력을 생성할 수 있습니다. Model은 정보를 검색하고, 생성된 내용의 품질을 실시간으로 평가하여, 사용자의 요구에 부합하는 맞춤형 결과를 제공합니다.
4. Empirical Results
본 논문에서는 Self-RAG의 성능을 평가하기 위한 metric으로 correctness, factuality, fluency를 이용했습니다. 또한, 다음과 같은 Dataset을 활용했습니다.
Closed-set Tasks
특정한, 미리 정의된 답변 집합에서 가장 적절한 답변을 선택하는 작업입니다. 모델은 제한된 선택지 중에서 가장 정확한 답변을 예측해야 합니다.
- PubHealth (Zhang et al. 2023): 공중보건에 관한 사실을 검증하는 데이터셋.
- ARC-Challenge (Clark et al. 2018): 과학 시험에서 추출한 다중 선택 추론 문제를 포함하는 데이터셋.
Short-form Generation Tasks
짧은 형태의 텍스트를 생성하여 단답형 질문에 대한 답변을 제공하는 작업입니다. 이러한 작업은 간결하고 정확한 사실 기반의 답변을 생성하는 데 초점을 맞춥니다.
- PopQA (Mallen et al. 2023): 드문 엔티티에 대한 질문을 포함하며, 해당 엔티티의 월간 위키피디아 페이지 조회 수가 100회 미만인 질문들로 구성된 데이터셋.
- TriviaQA-unfiltered (Joshi et al. 2017): 오픈 도메인의 사실 기반 질문에 대한 답변을 생성하는 작업을 위한 데이터셋. 공개적으로 사용 가능한 테스트 세트가 없어 이전 연구에서 제안된 검증 및 테스트 분할을 사용합니다.
Long-form Generation Tasks
보다 긴 형태의 텍스트를 생성하는 작업으로, 상세한 설명, 이야기 형식의 내용, 또는 복잡한 질문에 대한 답변을 생성하는 데 초점을 맞춥니다. 이러한 작업은 높은 수준의 유창성, 정확성, 필요한 경우 정확한 인용을 포함해야 합니다.
- ALCE-ASQA (Gao et al.): 긴 형태의 답변을 요구하는 질문에 대한 답변을 생성하는 작업을 위한 데이터셋. 복잡하고 상세한 텍스트 생성이 요구됩니다.
실험 과정에서 ‘IsREL’, ‘IsSUP’, ‘IsUSE’ token 각각에 1.0, 1.0 0.5의 가중치를 부여해주었다고 합니다.
실험 결과는 다음과 같습니다.
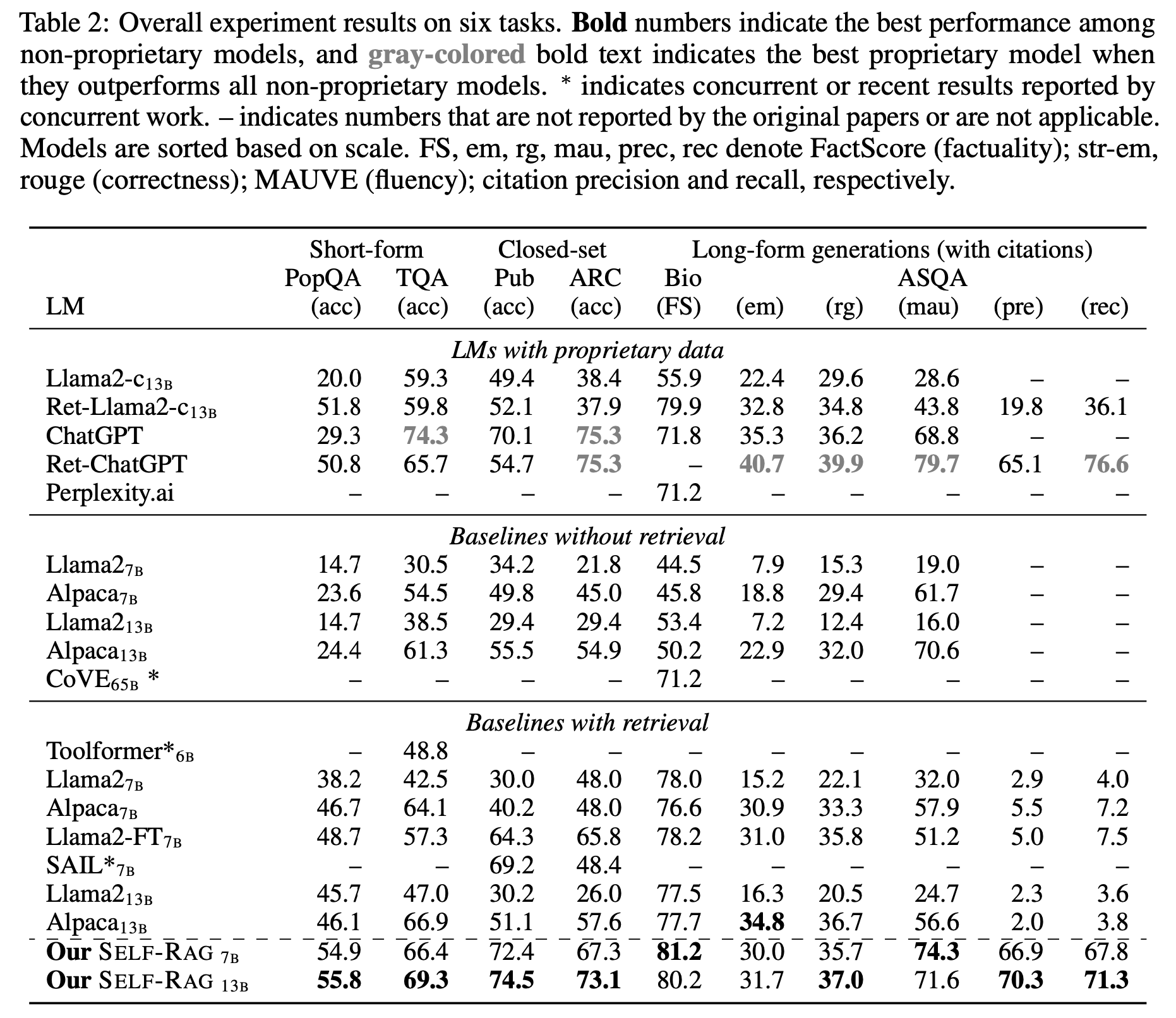
기준 모델 비교:
- Without retrieval : 사전 훈련된 LLMs(ex. Llama, Alpaca, ChatGPT)를 평가하고, 반복적 프롬프트 엔지니어링을 도입한 CoVE와 같은 모델과 비교합니다.
- With retrieval : 테스트 시간이나 훈련 중에 검색 메커니즘으로 보강된 모델을 평가합니다. 이에는 표준 RAG 기준 모델과 Ret-ChatGPT, perplexity.ai와 같은 독점 모델이 포함됩니다.
실험 설정:
- 다양한 출처에서 가져온 지시 사항을 따르는 입력-출력 쌍을 활용해, 총 150k 쌍으로 훈련을 진행합니다.
- 생성기로는 Llama2 7B 및 13B 모델을 사용하며, 검색기로는 입력당 최대 열 개의 문서를 검색하는 Contriever-MS MARCO를 사용합니다.
- 빈번한 검색을 장려하고 성능을 최적화하기 위해 특정 추론 구성을 설정합니다.
결과 및 분석:
- 주요 결과: Self-RAG model은 전통적인 LLMs 및 검색 메커니즘을 사용하는 모델들보다 PubHealth, PopQA, ASQA 작업에서 우수한 성능을 보입니다. 특히, 특정 지표에서는 ChatGPT보다도 뛰어납니다.
- 검색을 포함한 기준 모델: 검색을 포함한 LLMs가 상당한 이득을 보이지만, 검색된 문서에서 단순히 추출하는 것 이상의 작업에서는 종종 부족함을 보입니다.
- Ablation Study: Self-RAG 프레임워크의 각 구성 요소가 중요함을 나타내며, 주요 기능이 제거되거나 변경될 때 성능이 크게 떨어짐을 보여줍니다.
- 맞춤 설정 및 효율성: 추론 시간에 모델의 행동을 수정하는 무게 용어를 조정함으로써 model의 행동을 조절할 수 있는 능력을 보여줍니다.
결론: Self-RAG는 요구에 따른 retrieving 및 self-reflectiom mechanism을 통해 LLM 출력의 quality과 factuality을 향상시키는 혁신적인 framework로 소개됩니다. 이는 다양한 작업 및 지표에서 기존 model을 크게 뛰어넘는 성능을 입증하여, LLM 개발에서의 추가 정제 및 응용 가능성을 보여줍니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.