Paper Review - "The Power of Noise - Redefining Retrieval for RAG Systems" by Cuconasu et al., 2024
arXiv : https://arxiv.org/abs/2401.14887, Jan 2024
1. Contributions
LLM(Large Language Model)은 Text generation task과 Complex question-answering task에서부터 Information retrieval task에 이르기까지 상당한 퍼포먼스를 보여주었습니다. 그러나, 지금의 LLM은 Pre-trained된 지식에 한정된 답변을 한다는 것과 제한된 Context Window를 가진다는 한계가 있었습니다. 이러한 한계점은 책이나 긴 대화에 대한 처리를 어렵게 만들고 있으며, Hallucination의 문제로 이어질 가능성도 높게 만들고 있습니다. 이러한 이유 때문에 RAG(Retrieval-Augmented Generation) System은 NLP분야에서 기존의 한계를 뛰어넘을 수 있게 해주는 중요한 System으로 대두되고 있습니다. 본 논문의 핵심 기여는 다음과 같습니다.
- 1-1. IR(Information Retrieval) Component가 RAG에 미치는 영향을 분석했습니다.
- 1-2. Prompt와 문서의 관련성, 문서의 위치, Context에 포함된 문서의 수와 같은 요소들을 평가하여, 어떤 요소가 RAG System의 성능에 중요한지 분석했습니다.
- 1-3. Data에 무관한 문서인 Noise를 넣어주었을 때, 30% 이상의 Accuracy향상이 있었다고 합니다.
RAG System은 크게 보면 Retriever(IR)과 Generation(LLM)으로 구성됩니다. 본 논문에서는 Retriever에 해당되는 IR측면에서 RAG System에 대해서 살펴보았습니다.
2. Backgrounds
2-1. RAG(Retrieval-Augmented Generation) System
RAG는 LLM이 Text Generation을 하기 전에 신뢰할 수 있는 외부 데이터를 참고할 수 있도록 하는 프로세스입니다. 이는 LLM의 생성 능력을 활용하는 동시에 IR 메커니즘을 통해 얻은 외부 데이터를 결합하여, LLM이 더 다양하고 정확한 정보에 기반한 답변을 생성할 수 있는 구조입니다. 즉 IR메커니즘과 LLM의 융합으로 Pre-trained parametric memory와 non-parametric memory를 모두 활용한 것이 RAG System이라고 볼 수 있습니다.
- 2-1-1. RAG System의 작동 원리
- 사용자로부터 질문이나 입력을 받습니다.
- 입력에 기반하여 관련된 외부 데이터 소스에서 정보를 검색합니다. 이 때, 검색 알고리즘이나 모델을 사용하여 입력과 관련성이 높은 문서나 데이터를 찾아냅니다.
- 검색된 정보를 언어 모델의 입력과 통합하여, 모델이 더 많은 데이터를 받을 수 있도록 해줍니다.
- 통합된 입력을 바탕으로 언어 모델이 최종적인 답변을 생성합니다. 결과적으로 모델은 사전 학습된 지식과 새롭게 검색된 정보를 모두 활용하게 됩니다.
- 2-1-2. RAG System의 도전 과제
- 검색된 정보의 정확성과 질문과의 관련성을 높이는 것이 중요한 과제라고 생각됩니다.
- 효율적인 정보 검색을 위해서 검색 알고리즘이나 모델을 최적화하는 것도 중요한 과제라고 생각됩니다.
구체적인 Architecture는 다음과 같습니다.

이제 수식을 살펴보겠습니다.
RAG Model에서는 input sequence $x$를 통해 text document $z$를 검색해서 target sequence $y$를 생성하는데에 활용합니다. Model은 Retriever와 Generator로 구성됩니다.
\[\text{Retriever} : P_{\eta}(z|x)\] \[\text{Generator} : P_{\theta}(y_{i}|x, z, y_{1:i-1})\]Retriever는 $\eta$를 parameter로 하여 $x$가 주어졌을 때, 상위 K개의 text passage 분포를 return해줍니다. Generator는 $\theta$를 parameter로 하여 original input $x$, retrieved passage $z$와 i-1 번째 token까지 활용하여 i번째의 token을 생성해냅니다. 이 때, retrieved document를 latent variable로 다루게 됩니다. 논문에서는 RAG-Sequence와 RAG-Token으로 두 개의 Model을 제안했습니다
- RAG-Sequence Model
- RAG-Sequence model은 입력 Sequence $x$에 기반하여, 관련성 높은 상위 K개의 텍스트 문서 $z$의 분포를 반환합니다. 이 과정에서 검색 알고리즘은 입력에 가장 관련성 높은 문서를 식별하기 위해 $\eta$ 파라미터를 사용합니다.
$\text{Note) }$
$P(y|x) = \sum_{z}P(y,z|x) = \sum_{z} \frac{P(x,y,z)}{P(x)} = \sum_{z}\frac{P(z,.x)}{P(x)} * \frac{P(x,y,z)}{P(x,z)} = \sum_{z}P(z|x)P_{\theta}(y|x,z)$
$P_{\eta}(z|x) \propto \exp(d(z)^Tq(x)), \text{ }d(z) = \text{BERT}_d(z), \text{ }q(x) = \text{BERT}_q(x)$
이 때, $d(z)^Tq(x)$는 Document $z$와 Query $x$의 내적으로 문서와 질문 사이의 유사도를 구하여 관령성이 높은 k개의 문서를 찾는 과정이라고 볼 수 있습니다.
- RAG-Token Model
- 검색된 문서 $z$, 원본 입력 $x$, 그리고 이전까지 생성된 토큰 $y_{1:i-1}$을 기반으로, 다음 토큰 $y_i$를 생성합니다. 생성 과정에서 $\theta$ 파라미터를 사용하여 문서 $z$의 정보를 활용하게 됩니다.
- RAG-Sequence vs. RAG-Token
- RAG-Sequence: 전체 텍스트 생성에 단일 문서를 사용합니다. 이 모델은 전체 응답을 생성하기 위해 하나의 가장 관련성 높은 문서에 의존하는 구조입니다. 이 접근법은 문서가 전체 응답에 대해 충분한 정보를 제공할 때 유용합니다.
- RAG-Token: 각 토큰을 생성할 때마다 다른 문서를 참조할 수 있습니다. 이 모델은 각 토큰 생성 시 다양한 문서에서 정보를 가져올 수 있어, 보다 유연한 정보 활용이 가능합니다. 이는 특히 각 토큰이 다른 배경 지식을 필요로 할 때 유리합니다.
두 Model은 task과 data set에 따라서 성능이 달라졌고, 논문에서 각 모델의 장단점과 적합한 사용 사례를 제시하여 연구자들이 자신의 필요에 맞는 최적의 모델을 선택할 수 있도록 소개했습니다.
2-2. IR(Information Retrieval)
IR은 데이터베이스나 인터넷과 같은 대규모 데이터 집합에서 사용자의 Query에 가장 관련된 정보를 찾아내는 과정입니다. IR 시스템은 다양한 형태의 데이터(Text, Image, Video 등)에 적용될 수 있으나, NLP 분야에서는 주로 Text data를 대상으로 합니다. RAG 시스템에서의 IR 구성요소는 주로 텍스트 문서 검색에 초점을 맞추고 있습니다.
- 2-2-1. IR의 핵심 목표: 사용자의 질의에 대해 가장 관련성 높은 정보를 효율적으로 반환하는 것입니다. 이는 사용자가 필요로 하는 정보를 정확하고 빠르게 찾을 수 있도록 돕습니다.
- 2-2-2. IR의 작동 원리: 대부분의 IR 시스템은 다음과 같은 과정을 따릅니다.
- 질의 처리(Query Processing): 사용자로부터 받은 질의를 분석하여, 검색에 적합한 형태로 변환합니다.
- 문서 검색(Document Retrieval): 변환된 질의에 기반하여, 문서 집합에서 관련성이 높은 문서를 검색합니다. 이때, 다양한 검색 알고리즘과 indexing 기술이 사용됩니다.
- 랭킹 및 반환(Ranking and Returning): 검색된 문서들을 관련성에 따라 순위를 매기고, 사용자에게 결과를 반환합니다. 이 과정에서는 문서의 관련성을 평가하는 다양한 Metric이 사용될 수 있습니다.
- 2-2-3. RAG 시스템에서의 IR 역할: RAG 시스템에서 IR 구성요소는 입력된 질의와 관련된 외부 정보를 검색하는 역할을 합니다. 이를 통해 LLM이 생성할 텍스트의 정확성과 다양성을 향상시키는 데 기여합니다. 검색된 문서는 LLM이 생성 과정에서 참조하는 추가적인 지식 소스로 활용되어, LLM이 보다 정보에 기반한, 사실적인 텍스트를 생성할 수 있도록 돕습니다.
- 2-2-4. 도전 과제: IR 시스템의 주요 도전 과제는 정확성과 효율성의 균형을 맞추는 것입니다. 관련성이 높은 정보를 정확하게 검색하는 동시에, 대규모 데이터 집합에서 빠르게 정보를 찾아내야 합니다. 이를 위해 고급 검색 알고리즘과 색인 기술의 개발, 그리고 사용자 질의의 의도를 정확히 이해하는 자연어 처리 기술의 향상이 필요합니다.
IR 기술은 RAG 시스템에서 중요한 역할을 하며, 검색된 정보의 품질이 최종 생성물의 정확성과 풍부함에 큰 영향을 미칩니다. 따라서, 효과적인 IR 구성요소의 개발은 RAG 시스템의 성능을 극대화하는 데 핵심적입니다.
2-3. Beam Search
Beam Search는 가장 높은 확률을 가진 Sequence를 효율적으로 찾아내는 것입니다. Beam Search는 완전 탐색(full search)과 달리, 각 단계에서 가장 가능성이 높은 상위 ‘k’개의 후보만을 유지하며 탐색의 범위를 제한함으로써 계산 비용을 크게 줄입니다.
- 2-3-1. Beam Search의 작동 원리:
- 초기화: 탐색을 시작할 때, 시작 토큰(예: 문장의 시작을 나타내는 토큰)으로부터 시작합니다.
- 확장: 각 탐색 단계에서, 현재까지 생성된 각 Sequence를 다음 가능한 모든 Token으로 확장합니다. 이는 각 후보 Sequence에 대해 모든 가능한 다음 단어를 추가하는 것을 의미합니다.
- 가지치기(pruning): 확장된 모든 Sequence 중에서 확률이 가장 높은 상위 ‘k’개의 Sequence만을 선택합니다. 이 ‘k’를 beam size라고 하며, 이 값이 클수록 더 많은 Sequence를 탐색하게 됩니다. 하지만, 너무 큰 beam size는 계산 비용을 증가시키고, 때로는 일반화 성능을 저하시킬 수 있습니다.
- 종료 조건: 특정 길이에 도달하거나 종료 토큰(“<$\text{EOS}$>”)이 생성될 때까지 이 과정을 반복합니다.
- 결과 선택: 최종적으로 beam 내에서 가장 높은 총 확률을 가진 Sequence를 최종 출력으로 선택합니다.
2-3-2. 직관적인 예시:
예를 들어, beam size가 2인 상황에서 문장을 생성한다고 가정해봅시다. 첫 단어로 “I”가 선택되었다고 합시다. 다음 단어로 “am”, “have”가 각각 확률이 가장 높은 단어로 선택됩니다. 이제 “I am”, “I have” 두 Sequence를 가지고 다음 단어를 예측합니다. 만약 “I am”에 대해 “happy”, “a”가, “I have”에 대해 “a”, “the”가 다음으로 높은 확률의 단어로 선택된다면, 각각 “I am happy”, “I am a”, “I have a”, “I have the” 네 가지 Sequence를 얻게 됩니다. 이 중 확률이 가장 높은 상위 2개의 Sequence만을 다음 단계로 가져가는 방식으로 탐색을 진행합니다.
Beam Search는 높은 확률을 가진 Sequence를 효율적으로 찾아낼 수 있지만, 극단적인 경우 최적의 해를 보장하지는 않습니다. 이는 탐색 과정에서 다른 경로의 후보들이 일찍 제거될 수 있기 때문입니다. 그럼에도 불구하고, 실제 응용에서는 종종 우수한 성능을 보여주며, 계산 비용 대비 좋은 결과를 얻을 수 있는 타협점을 제공합니다.
3. Methodology
본 논문에서는 $P_{\theta}(y_i|x,z, y_{1:i-1})$에서 Retrieved document인 $z$가 변하면서 Generative component에 어떠한 영향을 미치는지 분석함과 동시에 가장 적절한 Set of document $D_{r}$을 찾아 효율적인 Retriever를 구성하여 RAG System의 Performance를 최대화시키는 것에 집중했습니다.
3-1. Dataset
Google의 NQ(Natural Questions) dataset을 이용하여 모델을 학습시켰습니다. NQ dataset은 Real-world query들이 담긴 대규모 데이터로 각각의 dataset은 사용자의 query와 이에 대응되는 답변을 담고 있는 Wikipedia 문서로 묶여있습니다.
3-2. Types of Documents
논문에서는 Query와의 관련성 및 관계에 기반하여 Document를 네 가지 유형으로 분류했습니다.
- Gold Document
- Wikipedia에서 Query에 대한 답변과 문맥적으로 직접적인 연관이 있는 문서로 구성되어 있습니다.
- Relevant Document
- Query에 대한 답변과 문맥적으로 유용한 문서로 구성되어 있습니다.
- Related Document
- Query와 의미론적으로(Semantically) 비슷하지만 답변을 포함하지 않는 문서으로 구성되어 있습니다. 특히 이 Document는 Generator가 관련 있는 정보와 관련 없는 정보를 구별하는 능력을 갖추는 데 중요한 역할을 합니다.
- Irrelevant Document
- Query에 대한 답변을 포함하지도 않고 관련도 없는 문서입니다. 이 Document는 모델이 전혀 관련 없는 정보를 처리하는 능력을 평가하는 데 중요합니다.
3-3. Document Retrieval
논문에서 전형적인 RAG에 따른 두 단계 접근 방식을 사용합니다.
- BERT 기반의 Dense retriever인 Contriever를 기본 검색기로 사용합니다. 이는 Contrastive loss를 사용하여 Supervision 없이 훈련됩니다.
- 약 2100만 문서로 구성된 Corpus 내에서 유사성 검색의 효율성을 높이기 위해 FAISS IndexFlatIP 인덱싱 시스템도 사용합니다.
추가적으로 각 문서와 쿼리의 Embedding은 모델의 마지막 Layer의 Hidden State를 평균내어 얻습니다.
3-4. LLM Input
Query를 받은 후, Retriever는 주어진 유사도 측정 기준에 따라 Corpus에서 top-K 문서를 선택합니다. 이 문서들은 작업 지시와 Query와 함께 LLM이 응답을 생성하기 위한 입력을 구성합니다. NQ-open 데이터셋은 답변이 최대 다섯 토큰으로 구성된 Query만을 포함하도록 구조화되었습니다. 따라서 LLM은 제공된 문서에서 최대 다섯 토큰으로 제한된 응답을 추출하는 작업을 수행합니다. 예시는 다음과 같습니다.

위의 사진에서 확인할 수 있듯이 Gold Document만을 LLM Input으로 했을 때, 오답을 생성하는 것을 확인할 수 있습니다.
4. Empirical Results
본 논문에서의 연구 결과는 매우 흥미롭습니다. 본문의 서론에서 연구자들은 다음과 같은 의문에 집중했다고 했습니다.
“What essential characteristics are required in a retriever to optimize prompt construction for RAG systems? Are current retrievers ideal?”
이 질문에 대한 대답이 논문 결과에서 나왔습니다.

위의 이미지에서 Related Document를 LLM Input으로 넣었을 때, 여전히 오답을 생성하는 것을 알 수 있습니다. 반면에 아래 이미지과 같이 Irrelevant Document를 Input으로 넣었더니 오히려 정답을 생성하는 것을 확인할 수 있습니다.

아래에서 구체적인 표들을 제시할 것인데, 표들을 통해서 실제로 Related Document는 모델의 성능에 악영향을 끼치는 반면에 Irrelevant Document는 성능을 개선하는 것을 확인할 수 있습니다.
아래의 Table 1은 Related Document가 어느 위치에 놓이든, 0개일 때 성능이 좋다는 것을 보여줍니다.
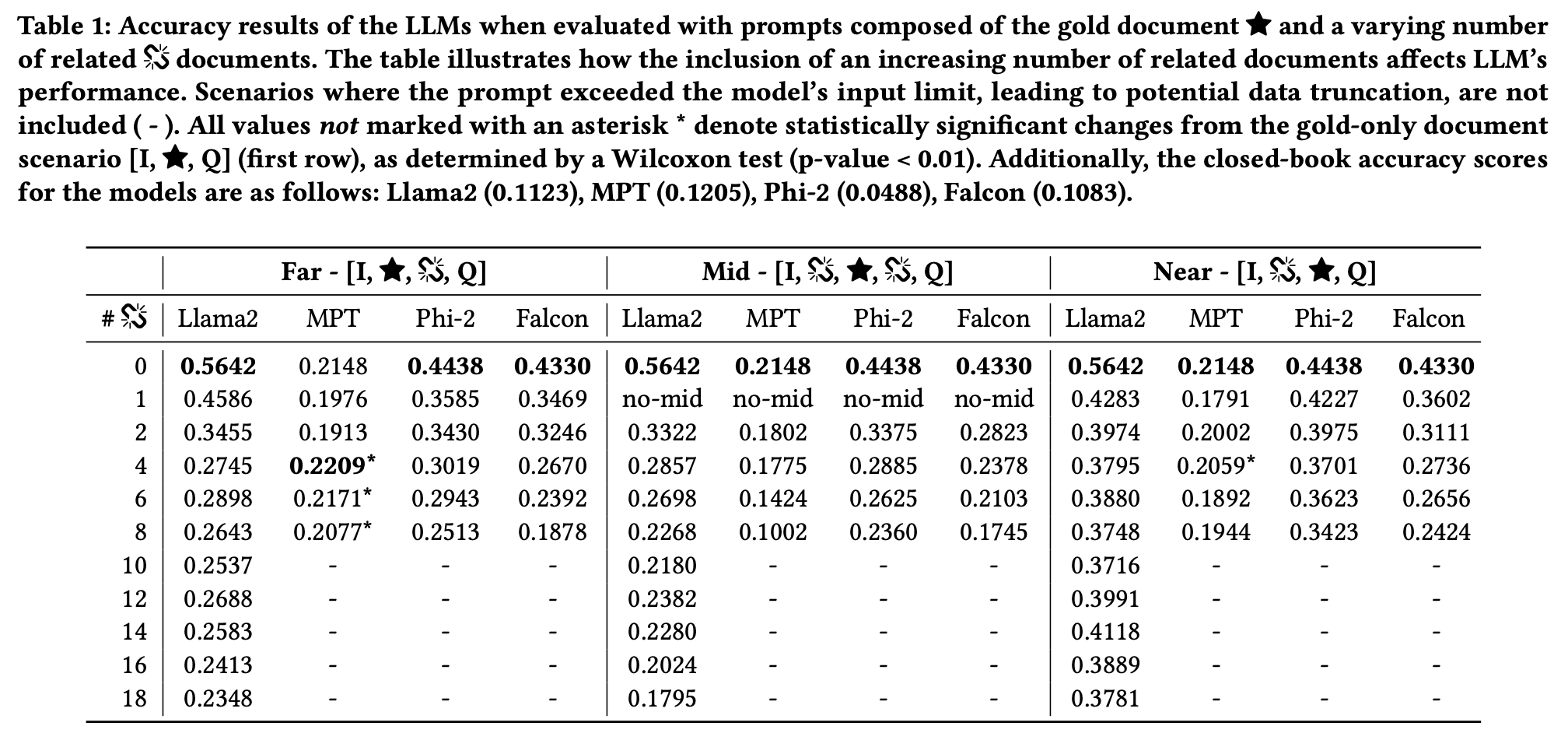
아래의 Table 2에서는 Llama2를 기준으로 Irrelevant Document가 14개이고 Gold Document가 Query와 가까울 때, Accuracy가 가장 높다는 것을 확인할 수 있습니다.
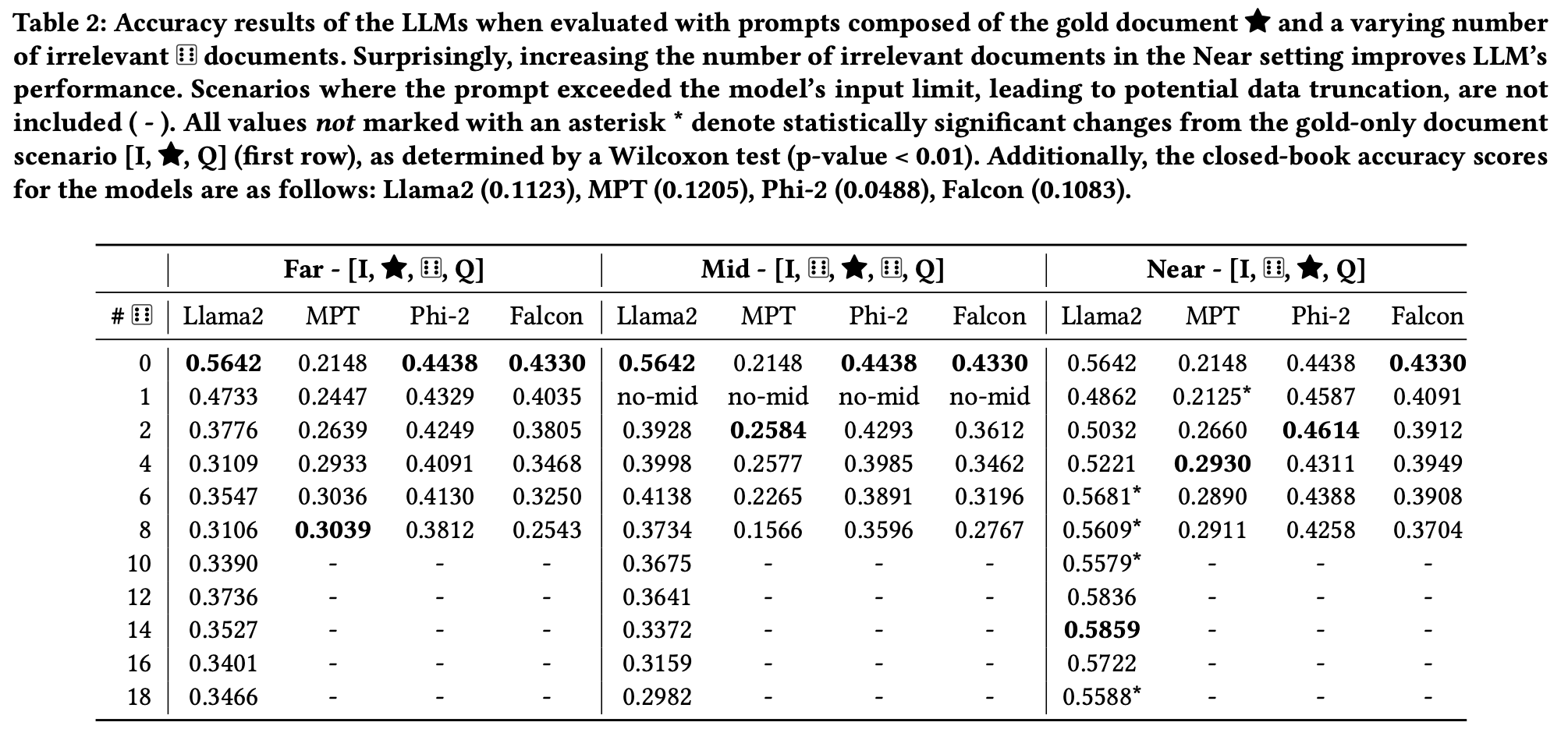
아래의 Table 3에서는Llama2-7b를 기준으로 Irrelevant document가 많을 때, 성능이 개선되는 것을 보여줍니다.
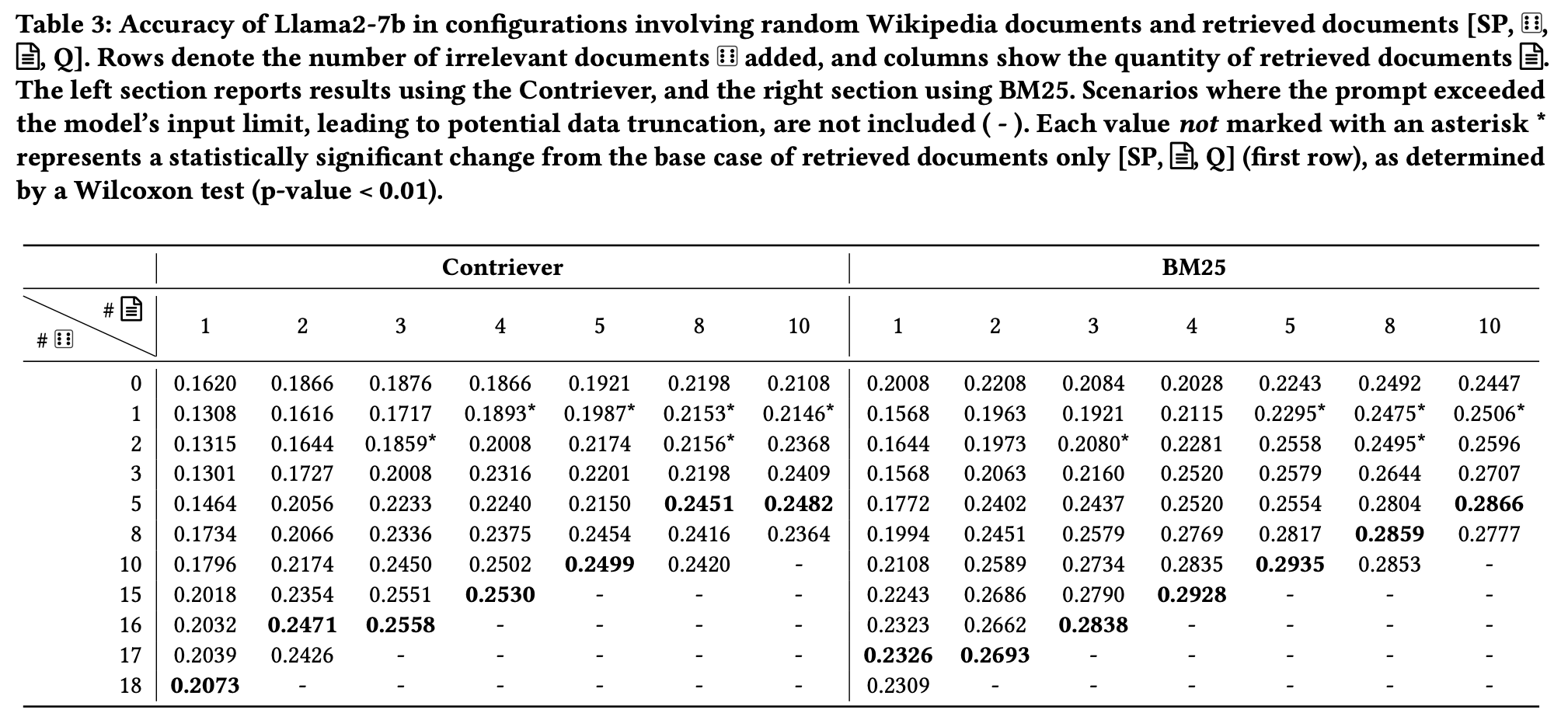
위의 표들을 확인할 수 있듯이, 논문에서는 RAG System을 위한 Prompt구성을 최적화 하기 위한 특성을 이해하는 데 중요한 발견을 했습니다.
- Irrelevant Document가 오히려 모델의 성능을 개선한다는 점을 발견했습니다.
- Related Document는 모델의 성능에 안 좋은 영향을 준다는 것을 발견했습니다.
- Retrieved Document의 위치 또한 성능에 영향을 미친다는 것을 발견했습니다.
- Gold Document가 Query의 근처에 놓이는 것이 좋다는 것을 발견했습니다.
특히, Related Document의 경우에는 의미론적으로(Semantically) 연관되어있지만, 실제 정답을 포함하고 있지 않아서, 모델에 혼란을 주는 것으로 보입니다. 위의 발견들을 통해 RAG System을 활용하기 위한 새로운 지평을 열었다고 생각합니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.