Paper Review - [NIPS 2013] "Distributed Representations of Words and Phrases and their Compositionality" by Mikolov et al., 2013
Conference : NeurlPS (Neural Information Processing Systems), 2013
1. Contributions
본 논문에서는 효율적이고 성능이 좋은 Embedding기법을 소개했습니다. 이와 관련된 핵심 내용들은 다음과 같습니다.
- 1-1. 본 논문에서는 훈련 속도를 단축하기 위해서(2~10배 빠름) 빈도가 높은 단어를 Subsampling 하는 방법론을 적용했습니다. 이는 자주 등장하는 단어들의 샘플링 비율을 줄여 모델이 더 드문 단어에 더 많은 주의를 기울이도록 함으로써 효율적인 학습이 가능하게 합니다.
- 1-2. Hierarchical softmax의 대안으로 Negative Sampling을 제안했습니다. 이 방법은 전체 어휘 대신 소수의 ‘네거티브’ 샘플만을 선택하여 계산 비용을 줄이면서도 효과적인 학습을 가능하게 합니다.
- 1-3. 기존에는 단어의 순서나 복합적인 의미를 포함하는 구문과 관용구를 적절히 처리하지 못한다는 한계를 지적했습니다.
- 예를 들어, ‘Air Canada’와 같은 고유명사는 단순히 ‘Air’와 ‘Canada’를 결합한 것 이상의 의미를 지니기 때문에, 이러한 복합적 의미를 포착하는 것이 어렵습니다.
- 이에 대한 해결책으로, 논문은 구문이나 관용구를 단일 단어로 간주하여 처리하는 방법을 제안합니다.
- ⇒ Vec(’Montreal Canadiens’) - Vec(’Montreal’) + Vec(’Toronto’) = Vec(’Toronto Maple Leafs’)
- 1-4. Additive Compositionality를 소개했습니다. Additive Compositionality는 각 개별 단어의 벡터를 합산함으로써 전체 구의 의미를 추정할 수 있다는 개념입니다. 이는 벡터 공간에서 의미적 관계를 선형적으로 조합할 수 있다는 시사합니다.
- ⇒ Vec(’Korea’) + Vec(’Capital’) = Vec(’Seoul’)
2. Backgrounds
Word Embedding - 단어를 실수로 구성된 벡터로 변환하여 표현하는 법으로 One-Hot Encoding이나 TF-IDF(term frequency-inverse document frequency)같은 방법이 있습니다. 그러나, Word Embedding만으로는 단어의 의미를 파악하는 것에 있어서 부족한 부분이 있었고, 이를 개선한 것이 Word2Vec입니다.
Word2Vec - 텍스트 내의 단어들을 문맥적 의미를 담을 수 있도록 벡터 공간에 mapping합니다. 이렇게 mapping된 단어 벡터는 단어 간의 의미적 관계를 수치적으로 표현할 수 있게 해주며, 이는 단어들의 문맥적 유사성을 반영합니다. 또한, Word2Vec 모델은 신경망을 기반으로 하며, 크게 두 가지 방식인 CBOW(Continuous Bag of Words)와 Skip-gram을 통해 훈련됩니다.
CBOW, Skip-gram 그리고 여기서 발전된 방법론들을 먼저 살펴보겠습니다.
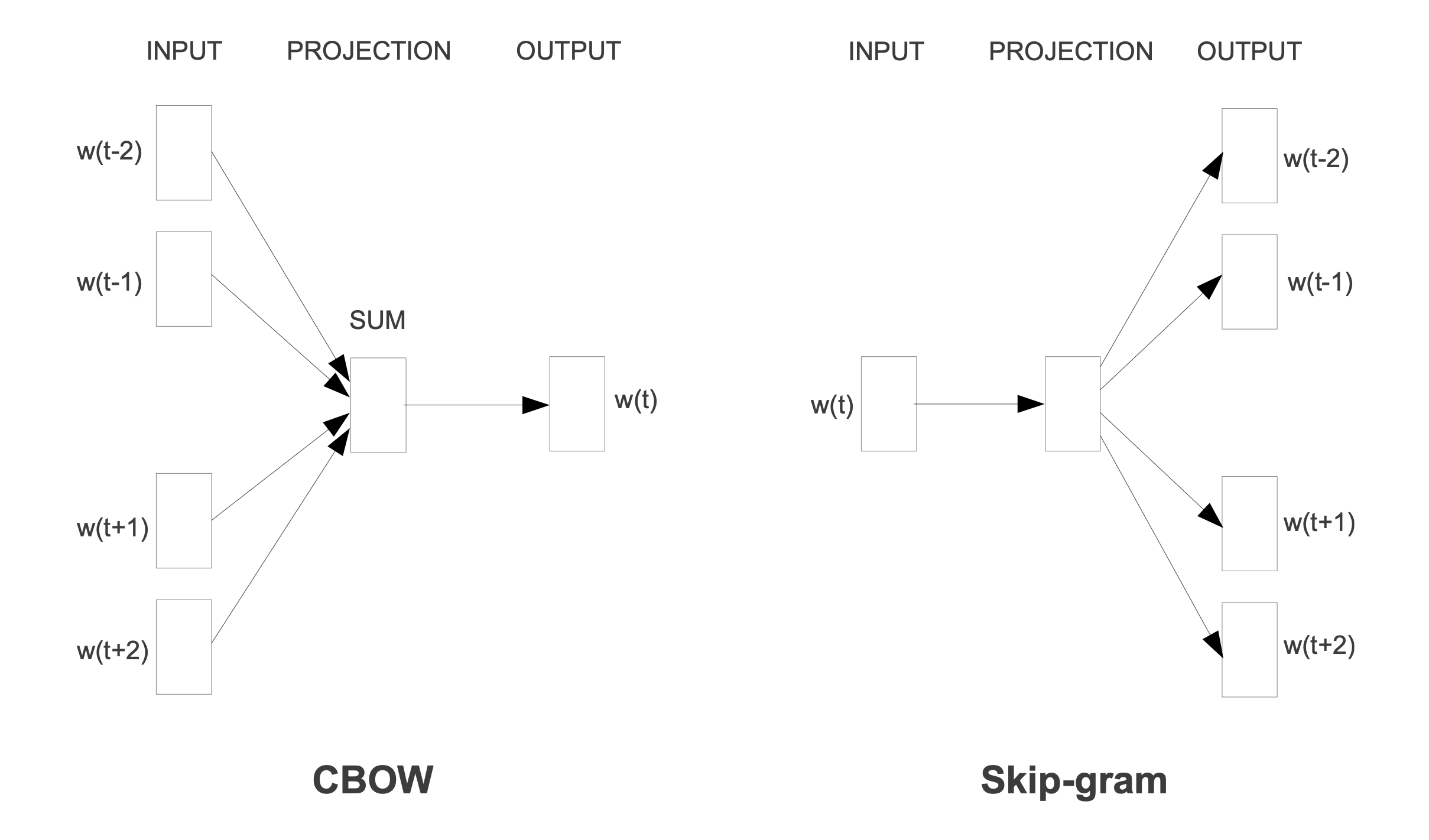
주변 단어들을 입력으로 사용하여 중심 단어를 예측합니다. 이 모델은 주변 단어들의 집합에서 정보를 추출하여 하나의 target 단어를 예측하는 데 집중합니다. CBOW는 주변 단어들의 평균적인 특징을 사용하여 중심 단어를 예측하기 때문에, 단어 예측 시 문맥 정보가 평균화 됩니다.
- CBOW는 주어진 주변 단어들의 집합으로부터 중심 단어를 예측하는 것입니다.
- “The quick brown fox jumps over the lazy dog” 라는 문장에서 ‘quick’, ‘brown’, ‘jumps’, ‘over’ 라는 주변 단어들을 통해서, CBOW모델은 ‘fox’라는 중심 단어를 예측하려고 시도합니다.
여기서 중요한 점은 CBOW모델에서는 단어들의 ‘순서’는 상관 없이 주변 단어의 ‘집합’으로만 중심 단어의 의미를 추론한다는 것입니다.
2-2. Skip-gram
Prediction based Embedding으로 중심 단어를 입력으로 사용하여 주변의 여러 단어들을 예측합니다. 즉, 한 단어가 주어졌을 때, 그 단어의 문맥 내에서 나타날 수 있는 주변 단어들을 예측하는 것이 목표입니다. Skip-gram은 특정 단어로부터 문맥 내의 여러 단어들을 예측하기 때문에, 각 단어 사이의 관계를 더 세밀하게 학습할 수 있습니다.
- Skip-gram에서는 ‘문장에서 비슷한 위치에 있는 단어는 비슷한 의미를 가질 것’을 가정합니다.
- Ex1) ‘똑똑한 학생’과 ‘영리한 학생’과 같이 ‘똑똑한’과 ‘영리한’ 이 비슷한 위치에서의 빈도가 높으면, 두 단어는 비슷한 의미를 갖는다고 학습합니다. 이러한 학습은 두 단어를 Embedding할 때, 비슷한 위치에 놓이도록 합니다.
- Ex2) ‘강아지’와 ‘개’ 또한 비슷한 위치에서 많이 사용되므로, 이 두 단어의 벡터를 서로 가깝게 위치하도록 Embedding합니다.
- “The quick brown fox jumps over the lazy dog” 라는 문장에서 ‘fox’를 통해 ‘quick’, ‘brown’, ‘jumps’, ‘over’ 를 예측하려고 시도합니다.
수식은 다음과 같습니다.
\[\mathcal{L} = \frac{1}{T} \sum_{t=1}^{T} \sum_{-c \leq j \leq c, j \neq 0} \log p(w_{t+j} | w_t)\]- $L$ 은 모델의 로그 가능도(log likelihood)를 나타냅니다.
- $T$ 는 텍스트 코퍼스 내의 전체 단어 수입니다.
- $c$ 는 현재 단어 $w_t$ 에 대한 문맥(context) 윈도우의 크기입니다.
- $w_{t+j}$ 는 주어진 현재 단어 $w_t$ 주변의 문맥 단어들을 나타냅니다.
- $\log p(w_{t+j} | w_t)$는 주어진 현재 단어 $w_t$ 가 주어졌을 때 문맥 단어 $w_{t+j}$의 조건부 확률의 로그입니다.
⇒ 두 모델 모두 단어 벡터를 생성하는 과정에서 문맥 정보를 활용하며, 이를 통해 단어 사이의 의미적 관계를 벡터 공간에 임베딩합니다. 일반적으로 Skip-gram의 성능이 더 좋습니다. 그러나 Skip-gram의 수식에서 확인할 수 있듯이, Corpora가 매우 큰 경우에는 연산을 $T$ 번 해야한다는 비효율성이 있습니다. 이를 개선한 것이 Hierarchical Softmax입니다.
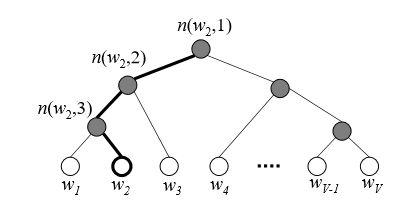
Hierarchial Softmax는 Full Softmax에 근사하며, Computing측면에서 Skip-gram보다 효율적입니다. 기존에 Corpora가 $W$개 였다면, Skip-gram에서는 $W$개의 output nodes를 계산해야했지만, Hierarchical Softmax에서는 $log_{2}W$만큼의 output nodes만을 계산하면 됩니다. Hierarchical Softmax의 수식만 적어두고, 이와 관련된 해석은 나중에 따로 다루겠습니다.
\[p(w|w_I) = \prod_{j=1}^{L(w)-1} \sigma \left( \left[ \left[ n(w, j + 1) = \text{ch}(n(w, j)) \right] \right] \cdot v'_{n(w,j)}\top v_{w_I} \right)\]Where
- $\text{ch}(n)$ be an arbitrary fixed child of n
- $\sigma(x) = \frac{1}{1 + \exp(-x)}$
- $p(w|w_I)$ is the conditional probability of the output word $w$ given the input word $w_I$
- $L(w)$ is the length of the binary tree path for the output word $w$
- $n(w, j)$ represents the node in the binary tree path for the word $w$
- $v’{n(w,j)}$ and $v_{w_I}$ are the vector representations of the output node and the input word, respectively.
and, \(\left[ \left[ x \right] \right] = \begin{cases} 1 & \text{if } x \text{ is true} \\ -1 & \text{otherwise} \end{cases}\)
Noise Contrastive Estimation (NCE)은 복잡한 확률 분포를 학습하는 데 사용되는 효율적인 기법입니다. NCE의 주요 아이디어는 모델이 실제 데이터와 생성된 노이즈 데이터 사이를 구별함으로써, 복잡한 확률 분포의 파라미터를 학습할 수 있다는 것입니다. 이 접근 방식은 특히 어휘 사이즈가 큰 언어 모델링 문제에서 계산 효율성을 크게 향상시킵니다.
- 기본 원리 : NCE는 로지스틱 회귀를 사용하여 실제 데이터와 노이즈 데이터를 구별하는 분류 문제로 변환합니다. 이 과정에서 모델은 데이터의 복잡한 확률 분포를 간접적으로 학습하게 됩니다.
- 효율성 : 전통적인 softmax 함수를 사용할 때보다 계산 비용을 크게 줄일 수 있습니다. 이는 각 학습 단계에서 전체 어휘 대신 소수의 노이즈 샘플만을 고려하기 때문입니다.
적용 : NCE는 본 논문에서 제안된 Negative Sampling의 기반이 되며, 언어 모델을 포함한 다양한 자연어 처리 Task에서 널리 사용됩니다.
2-5. Analogical Reasoning Task
Analogical reasoning task는 언어 모델이나 단어 Embedding Model의 능력을 평가하는 방법 중 하나입니다. 이 작업은 모델이 단어 간의 의미적 및 구문적 유사성을 얼마나 잘 이해하고 추론할 수 있는지를 평가합니다. 일반적으로 “A는 B에 대해 C는 D에 대한 것과 같다”는 형태의 질문으로 구성되며, 모델은 주어진 A, B, C 단어를 바탕으로 D를 예측해야 합니다.
3. Methodology
Corpora(말뭉치 - 데이터)가 매우 클 때에는 ‘in’, ‘the’, ‘a’ 와 같이 유의미한 정보를 담고 있지 않은 단어들이 압도적으로 높은 빈도를 갖게 됩니다. 이에 착안하여, 빈도가 높은 단어에는 확률 값을 낮게 주고, 빈도가 낮은 단어에는 확률 값을 높게 줌으로 단어들을 효율적으로 Sampling할 수 있게 해줍니다.
수식은 다음과 같습니다.
\[P(w_{i}) = 1 - \sqrt{\frac{t}{f(w_{i})}}\]Where
\[f(w_{i}) : Frequency\; of \; word \;w_{i}\] \[t \; is \; chosen \; threshold, \; typically \; around \; 10^{-5}\]위의 Subsampling기법으로 훈련 속도는 약 2~10배가 빨라졌으며, 비교적 빈도가 낮았던 단어들에 대해서 정확도가 상승했다고 합니다.
Word2Vec 모델, 특히 Skip-gram 모델에서, 모든 단어에 대한 예측을 수행하는 것은 매우 계산 비용이 높습니다. 전체 어휘집(Vocabulary)의 크기가 크면, 각 훈련 단계에서 모든 단어에 대한 확률을 계산하고 업데이트해야 하므로 효율성이 떨어집니다. Negative Sampling은 이 문제를 해결하기 위해 소수의 ‘Negative’ 샘플(즉, 타겟 단어가 아닌 단어들)만을 무작위로 선택하여 업데이트하는 방식을 채택합니다. 이 때, 문맥 속에 존재하지 않는 단어들을 Noise(Negative Sample)로 간주하고, Negative 단어들의 Unigram 확률분포를 통해 Sampling합니다.
- 과정
- Positive Sample 처리: 주어진 단어(중심 단어)로부터 그 주변에 나타나는 단어(문맥 단어)의 관계를 Positive Sample로 간주하고, 이를 모델이 예측하도록 합니다.
- Negative Sample 선정: 동시에, 모델은 무작위로 선택된 ‘Negative’ 단어들(즉, 문맥에 실제로 나타나지 않은 단어들)에 대해서는 해당 중심 단어 주변에 나타나지 않을 것이라고 예측하도록 합니다. 각 Positive Sample에 대해 소수의 Negative Sample(예: 5~20개)을 사용합니다.
- 목적 함수 최적화: 모델은 이 Positive Sample과 Negative Sample을 사용해 목적 함수를 최적화하며, 이 과정에서 중심 단어와 문맥 단어 사이의 관계를 학습합니다. 목적 함수는 Positive Sample에 대해서는 확률을 최대화하고, Negative Sample에 대해서는 최소화하는 방식으로 구성됩니다.
3-3. Score Function
Contribution에서 언급했듯이, 기존에는 단어의 순서나 복합적인 의미를 포함하는 구문과 관용구를 적절히 처리하지 못한다는 한계가 있었습니다. 이를 위해서, 자주 등장하는 단어 조합을 찾을 수 있는 Score Function이 소개되었습니다. 단어의 조합을 Score Function에 넣어 계산한 Score가 특정 기준을 넘으면 해당 단어의 조합을 하나의 단어로 취급합니다. 이렇게 함으로, 두 단어의 조합이 전혀 다른 뜻을 가진 새로운 단어가 된다는 것을 반영할 수 있게 됩니다.
$score(w_i, w_j)$ 는 다음과 같이 계산됩니다:
\[score(w_i, w_j) = \frac{\text{count}(w_i) \times \text{count}(w_j)}{\text{count}(w_i, w_j) - \delta}\]여기서:
- $\text{count}(w_i, w_j)$는 단어 $w_i$와 $w_j$가 함께 등장하는 빈도를 나타냅니다.
- $\delta$는 특정 임곗값이나 조정 파라미터를 의미하며, 단어조합 빈도가 이 값을 초과하는 경우에만 단어 쌍을 유의미하게 고려합니다. 이는 단어조합의 빈도가 낮은, 즉 무작위적으로 함께 나타날 가능성이 높은 단어 쌍의 영향을 줄이기 위해 사용됩니다.
- $\text{count}(w_i)$와 $\text{count}(w_j)$는 각각 단어 $w_i$와 $w_j$의 전체 문서 내 등장 빈도를 나타냅니다.
4. Empirical Results
본 논문에서는 Analogical reasoning task에서 Negative Sampling이 Hierarchical Softmax와 Noise Contrastive Estimation을 Outperform했다고 주장합니다. 또한, Subsampling기법으로 훈련 속도를 개선하였고, 단어를 더욱 정확하게 표현할 수 있게 되었다고 합니다.
Analogical reasoning task에 쓰인 Test는 다음과 같습니다.
- Semantic Test - “Germany” : “Berlin” :: “France” : $x$ 를 제안했습니다. $x$는 vec(”Berlin”) - vec(”Germany”) + vec(”France”)와 가까운 vec($x$)를 찾는 것으로 유추하게 됩니다. 위의 예시에서 $x$는 프랑스의 수도인 “Paris”가 적절해보입니다.
- Syntactic Test - “quick” : “quickly” :: “slow” : “$x$” 같은 task도 제안되었습니다. 여기서 $x$는 “slowly”가 적절해보입니다.
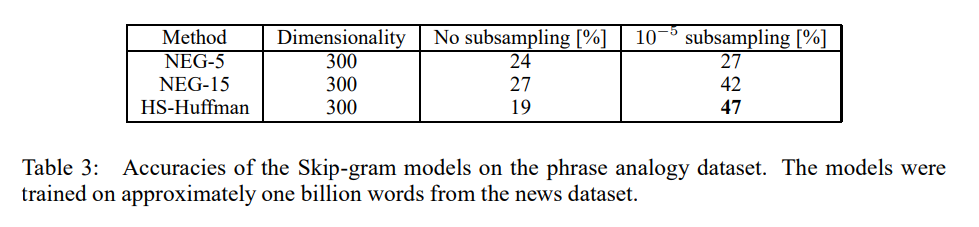
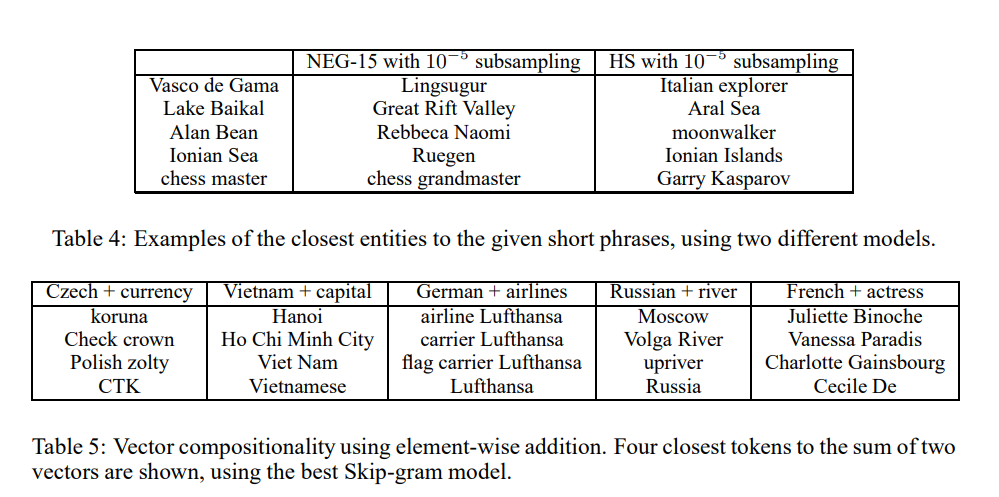
본 논문에서는 Skip-gram 모델을 통해 단어와 구문의 효과적인 Distributed Representation을 학습하는 방법을 제시합니다. 이러한 Distributed Representation은 선형 구조를 지니고 있어, 단순한 벡터 연산을 통한 정밀한 유추 추론을 가능하게 합니다. 또한, Negative sampling과 같은 새로운 훈련 방법을 도입하여, 대규모 data set에서도 빠른 훈련 속도와 좋은 표현력을 달성했습니다. 또한, 단어 벡터의 간단한 덧셈을 통해 의미 있는 단어 결합을 가능하게 하며, 이를 통해 더 긴 텍스트 조각을 간단하고 효율적으로 표현할 수 있는 새로운 방법을 제공했다고 생각합니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.