Paper Review - "HiQA ; A Hierarchical Contextual Augmentation RAG for Massive Documents QA", Xinyue Chen et al., Feb 2024
Conference : arxiv, Feb 2024
1. Contributions
최근 RAG System 관련해서 많은 연구들이 이루어지고 있으며, QA(question-answering) methodology는 유의미한 진보들이 있었습니다. RAG System을 통해서 LLM의 답변 quality가 좋아지기도 하고, hallucination을 줄이기도 했습니다. 그러나 Retriever가 방대한 양의 구별하기 어려운 document를 다룰 때에는 한계가 있었습니다. 본 논문에서는 방대한 document에서도 잘 작동하는 framework로 HiQA를 제안했습니다. 본 논문의 핵심 기여는 다음과 같습니다.
1-1. 기존의 standard RAG-based document QA system에는 document를 구조화되지 않은 chunk로 다루었습니다. 이러한 접근법은 복잡한 구조를 갖고 있는(Table, Image, other structural information) document관련해서는 한계를 직면한다고 합니다. 논문에서는 document의 구조적 정보를 retrievable metadata로 추출하는 기여를 했습니다.
1-2. 기존에 Metadata를 이용해서 hard partitioning을 하는 전략이 있었습니다. 이러한 전략은 IR(Information Retrieval)과정을 하기 전에 pruning(가지치기)와 selection을 통해서 이루어집니다(segment의 size를 줄이는 방식). 그러나, Hard partitioning은 complex task(such as cross-document searches or multi-product comparison)에서는 중요한 정보들이 사라지는 문제점이 있었습니다. 이와 관련해서, Soft partitioning을 제안했습니다.
1-3. MDQA(Multi-Document Question-Answering)에서는 document사이의 관련성을 고려하고 document들 끼리 구분을 짓는 것이 직면한 과제라고 합니다. LLM을 통해서 서로 다른 document들에 있는 정보를 통합하는 연구는 많이 진행되고 있지만, Similar document에 대해서는 잘 다뤄지지 않았다고 합니다. 실제로 Large-scale document에서는 비슷한 구조와 내용을 담고있는 doucment가 많습니다. 이러한 문제를 해결하기 위해서 논문에서는 Metadata-based embedding augmented method와 Multi-Route retrieval mechanism의 결합을 제안했습니다.
위의 기여와 함께 HiQA는 multi-document environment에서 SOTA를 달성했다고 합니다.
*Metadata : Metadata는 다른 데이터를 설명하는 데이터입니다. 간단히 말해서, Metadata는 데이터에 대한 데이터로, 어떤 콘텐츠나 객체의 정보를 요약하는 레이블 또는 기술적 세부사항을 포함합니다. 메타데이터는 데이터의 내용, 품질, 조건, 기원 등에 대한 정보를 제공하여, 데이터의 검색, 이해, 관리, 사용을 용이하게 합니다.

해당 사진은 제가 GPT4.0에게 직접 물어보면서 얻은 사진입니다. RAG System이 어떻게 작동하는지 시각적으로 보여드리기 위해서 가져왔습니다. 먼저 GPT4.0에게 CA-IF1042에 대한 설명과 diagram을 요구했는데, 사전학습 된 데이터에 기반한 LLM이기 때문에, ‘관련있는 source를 찾는데 어려움을 겪었다’라고 답변을 하며 적절한 답변을 하는 데에 있어서 한계가 있음을 알 수 있습니다.
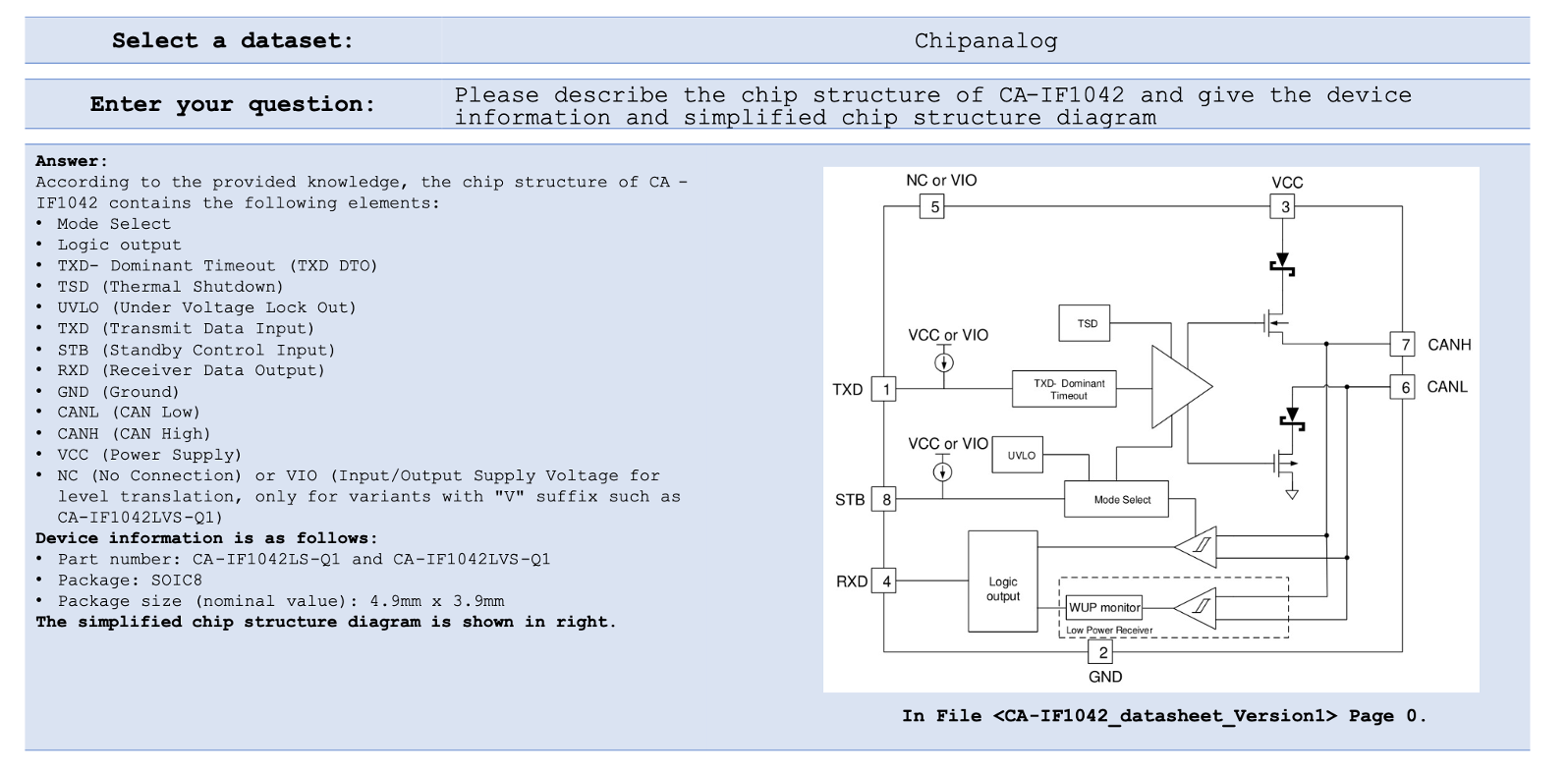
반면에, RAG System을 통해서 내부적으로 갖고있는 database에 retriever가 접근하여 document를 추출해 prompt에 같이 넣어줌으로 똑같은 질문에 대해서 이와 같은 output을 만들어낼 수 있게 됩니다. 또한, 요구했던 diagram까지도 불러온 것을 확인할 수 있습니다.
이처럼 굉장히 domain-specific한 task나, 회사 내부에서만 취급되는 기밀 문서에서도 LLM을 활용할 수 있는 방안이 RAG System입니다. 세간에 돌아다니는 방대한 데이터를 매 순간 LLM에 학습시키는 것은 시간적으로도 비용적으로도 비효율적이기 때문에, LLM을 학습시키지 않고도 이와 같은 출력을 만들어낼 수 있는 RAG System이 점차 주목을 받고있기도 하고, 특히 industry에서 관심을 많이 가질 것이라고 생각합니다.
2. Backgrounds
2-1. Document QA vs Multi-Document QA
- 2-1-1. Document QA
Document QA(Document Question Answering)은 단일 문서에서 답변을 추출하는 데 사용됩니다. PDF와 같은 구조화된 문서를 처리하는 데 유용하며, Table, Image, Section과 같은 구조적 요소를 잘 이해하는 것이 중요합니다.- PDFTriage는 구조화된 문서에 대한 QA 작업에 중점을 두며, 구조적 요소를 추출하고 이를 검색 가능한 metadata로 변환합니다. 이 방식은 Standard RAG based document QA system에서는 어려워하는 복잡한 질문에 답할 수 있게 합니다. (e.g. ’Can you summarize the key points on page 5-7?”, or “In which year did Table 3 record the hidhes income?”)
- PaperQA는 Scientific Research QA를 위한 에이전트로서, 관련 논문을 찾는 Search component, 관련 텍스트를 수집하는 Gather evidence component, 수집된 증거를 기반으로 답변을 생성하는 Answer question component로 구성됩니다.
- 2-1-2. Multi-Document QA
Multi-Document QA(MDQA)는 여러 문서 간의 관계와 차이점을 고려해야 합니다. 단일 document를 다루는 것보다 많은 어려움을 유발합니다. MDQA는 다음과 같은 과정으로 이루어져있습니다.- 1.LLM을 활용하여 복잡한 질문을 더 간단한 하위 질문으로 분해합니다.
- 2.Search engine을 활용하여 각 하위 질문에 대해 multi document에서 candidate paragraph content를 추출합니다.
- 3.LLM을 사용하여 paragraph contents를 입력받고 답변을 생성합니다.
본 논문에서는 multi-document QA에 대해서 다루었습니다.
2-2. PDFImage-Searcher
PDFImage-Searcher는 PDF 문서 내의 Image로부터 Contents를 추출하고 이해하기 위해 설계된 도구입니다. Graph, Chart, Table과 같은 Image는 직접적인 답변을 제공할 수 있는 중요한 정보를 담고 있습니다. PDFImage-Searcher를 QA framework에 통합하는 것은 retriever에서 multimodal 데이터를 사용하는 것으로 한 단계 발전시킵니다.
3. Methodology
HiQA System에서는 Markdown Formatter(MF), Hierarchical Contextual Augmentor(HCA), Multi-Route Retriever(MRR)로 3가지 Component로 구성되어 있습니다. 위 3가지 component를 통한 HiQA의 Framework는 아래 사진과 같습니다.
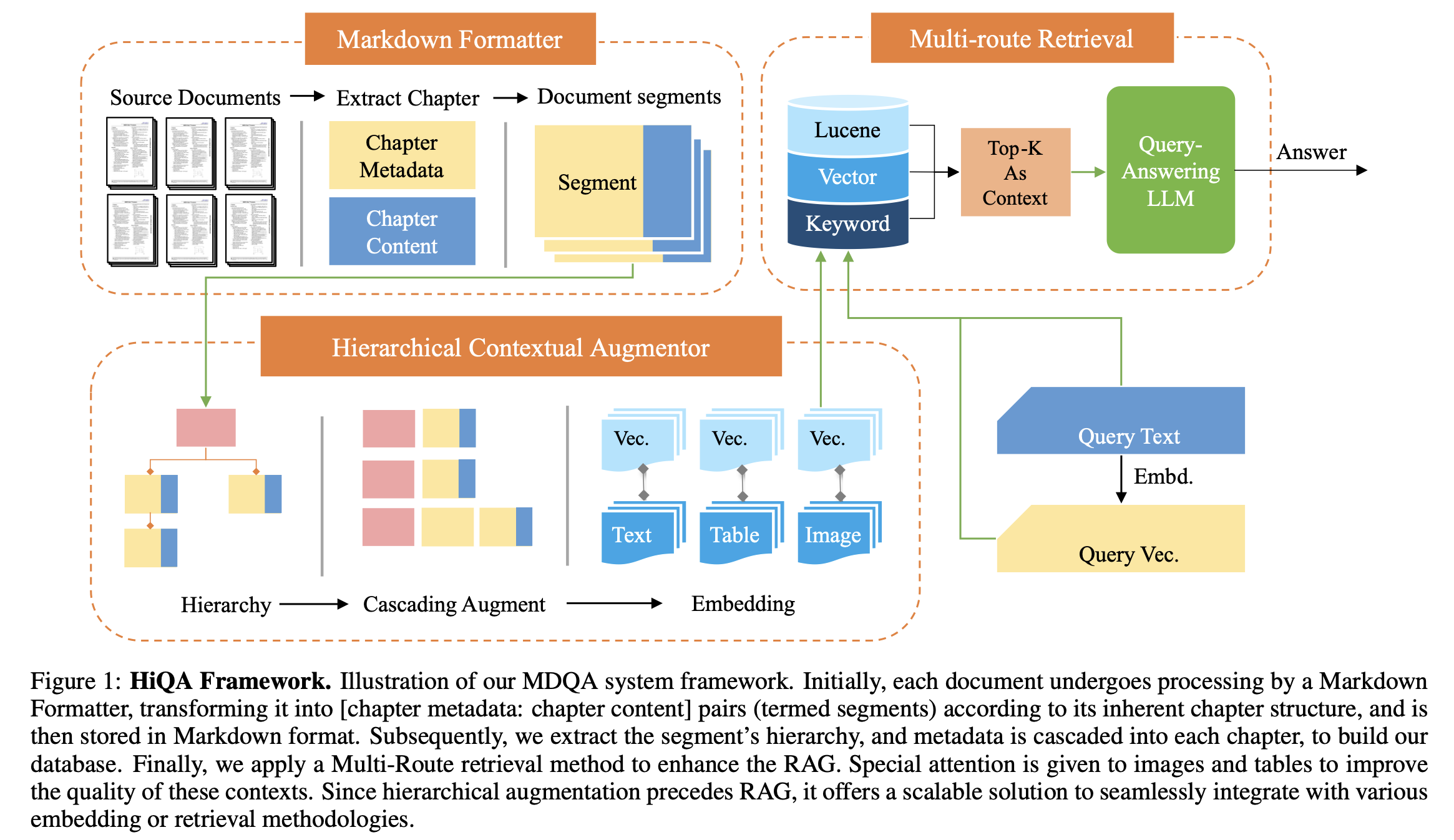
위의 Framework를 구성하는 요소들을 하나하나 살펴보도록 하겠습니다.
3-1. Markdown Formatter(MF)
MF module은 검색해온 문서를 segment들의 sequence로 구성된 markdown으로 변환하는 작업을 합니다. 이 때, 각각의 segment는 document의 chapter와 그에 해당하는 content를 포함하도록 하여 metadata를 추출하기 쉽도록 만들어 줍니다. 이러한 과정은 LLM을 통해서 이루어집니다.
그러나 LLM은 제한된 Context window를 가진다는 한계가 있습니다. 이러한 문제를 보완하기 위해서 논문에서는 sliding window technique라는 것을 이용했습니다. Window의 사이즈를 $W$라 하고, additional padding을 $K$개 그리고 document의 길이가 $N$이라고 할 때, 총 $T = [N/W]$번의 processing이 필요하다고 합니다. 이에 대한 예시를 아래 사진에 첨부했습니다.
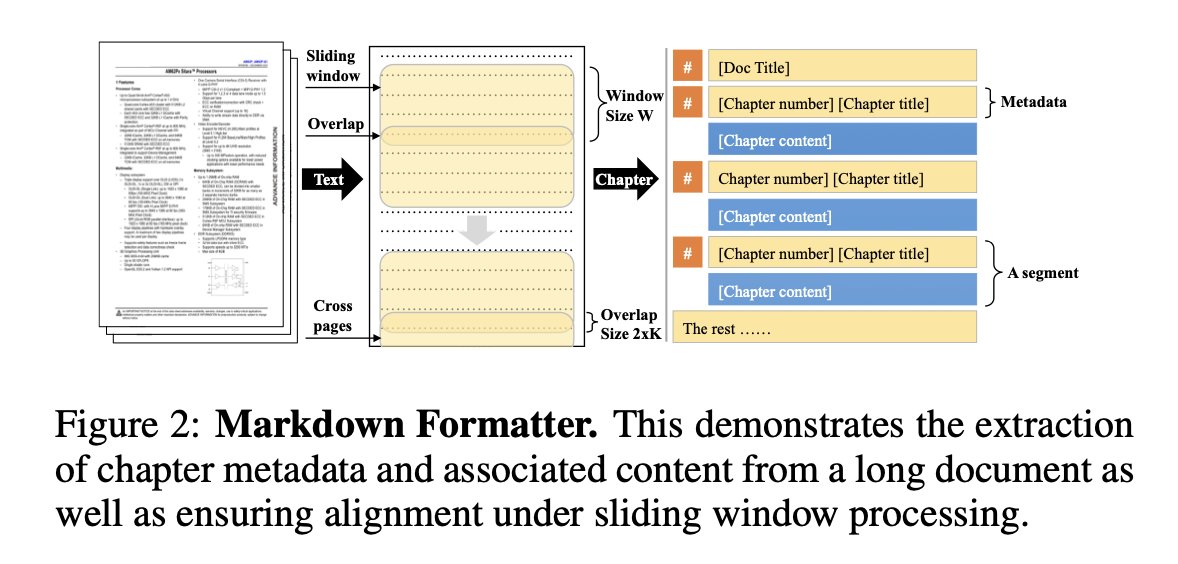
위 사진에서 Overlap이 되는 부분에 Context window size로 인해 중간에 잘림이 발생하는 부분입니다. 예를 들어서 “I am student”에서 context window size로 인해 “I am”까지만 들어간다면 “student”라는 중요한 정보를 잃게 됩니다. 이러한 문제를 해결하기 위해서 잘림이 발생하는 부분을 overlap한다고 이해할 수 있습니다.
수식으로 구체적인 방법론을 살펴보면 다음과 같습니다.
$M_c$ : LLM
\(D_{I} : \{D_{I}^{(1)}, D_{I}^{(2)}, \ldots, D_{I}^{(T)}\}\), LLM에 들어갈 document
\(D_{M} : \{D_{M}^{(1)}, D_{M}^{(2)}, \ldots, D_{M}^{(T)}\}\), LLM의 Output (Markdown-formatted document)
라고 할 때, $D_{M}^{(t)}$는 다음과 같이 생성됩니다.
\[D_{M}^{(t)} = M_{C}(D_{I}^{(t)}, D_{I}^{(t-1)},D_{M}^{(t-1)})\]위에서 $(D_{I}^{(t-1)},D_{M}^{(t-1)})$이 들어가는 이유는 LLM이 Overlap되는 부분에 대해서 인지하고 활용하기를 원해서 입니다.
또한, 본 논문에서는 PDFImage-Searcher를 이용해서 document내에 있는 Image또한 $D_{G}$로 추출하였습니다. Image의 title과 Image주변의 text 그리고 VLM(Vision-Language Model)을 활용하여 생성한 Image에 대한 설명(Optional)을 추출하여, 이 또한 Metadata로 추출하기 쉬운 형태 만들어주었다고 합니다.
\(D_{G} : \{I_{1}(\text{File}_{1}, \text{Desc}_{1}),I_{2}(\text{File}_{2}, \text{Desc}_{2}) \ldots\}\), Image data
이렇게 해서 생산된 Markdown은 Sturucture에 대한 정보가 담겨있는 metadata를 추출하기 쉬운 형태를 갖게 됩니다.
3-2. Hierarchical Contextual Augmentor(HCA)
HCA module은 MF에서 만든 Markdown을 이용하여 Hierarchical metadata를 추출하여 활용하는 module입니다. 특히, Metadata에 담겨있는 document의 구조적 정보를 활용해서 Text, Table, Image에 따라서 각각 다른 방식으로 augmentation을 하게 됩니다.
- 3-2-1. Text Augmentation
본 논문에서는 Text Augmentation과정에서 Doc title - Title1 - Title 1.1 - content순서로 metadata를 cascading을 하여 document의 구조를 이용했습니다.아래 사진과 같이 Cascading을 해줌으로써 각 Chapter의 정보를 체계적으로 연결하고, 깊은 곳에서부터 검색을 하는 방식으로 문서의 구조와 내용을 보다 명확하게 이해한다고 합니다. 특히, 이러한 방식은 정보를 효율적으로 처리해줄 수 있게 해주며, 관련된 정보를 쉽게 찾아낼 수 있도록 해준다고 합니다.
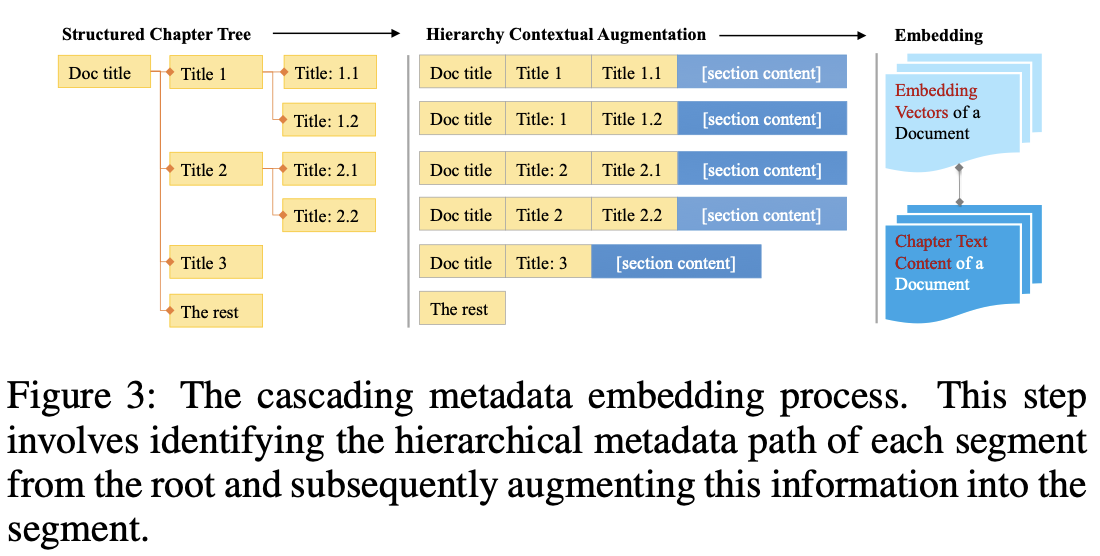
- 3-2-2 Table Augmentation
기존의 Chunk-based RAG method는 Table에 들어있는 숫자들이 일종의 noise로 작용하기 때문에, Table data를 이용하는데 어려움이 있었다고 합니다. 본 논문에서는 Table에 들어있는 숫자들이 noise로 작용하지 않기 위해서, Table의 title과 row/column label과 같은 Semantic element를 활용한다고 합니다.

- 3-2-3 Image Augmentation
Image Augmentation단계에서는 Image를 둘러싸고있는 Text들을 활용하고, Image자체에 대해서는 VLM(Vision-Language Model)을 통해서 Image를 설명하는 Caption을 활용한다고 합니다.
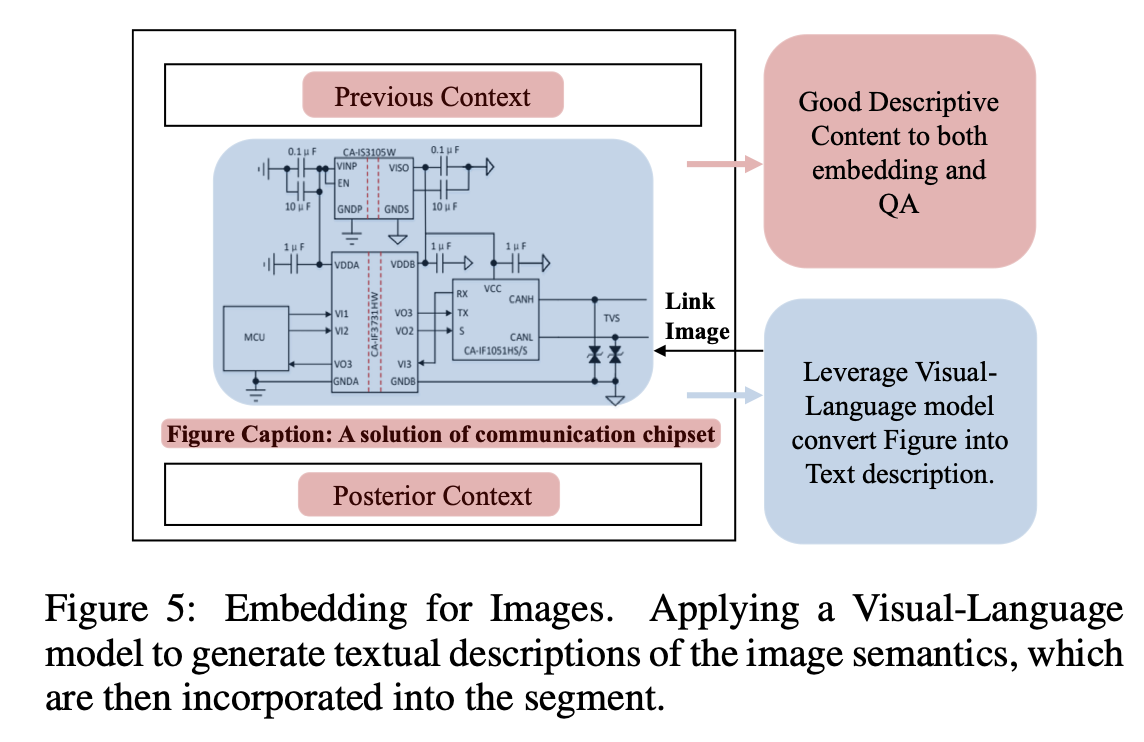
위와 같은 Augmentation단계를 끝낸 뒤에는 각각을 Embedding하여 vector database에 저장해줍니다.
3-3. Multi-Route Retriever(MRR)
MRR module은 LLM에 들어가기에 가장 적절한 segment를 찾기 위한 module입니다. MRR에서는 Vector similarity matching, Elastic search, Keyword Matching을 통해서 segment를 찾고자하는 시도를 했습니다.
- Vector similarity matching에서는 Query와 retrieved segment사이의 유사성을 판단해줍니다.
- Elastic search에서는 Vector similarity matching에서 놓칠 수 있는 word-level수준의 유사성을 판단해줍니다. 즉, vector similarity matching을 보완해준다고 볼 수 있습니다.
- Keyword matching은 Critical Named Entity Detection(CNED) method를 활용하여, entity 수준에서의 keyword가 몇 개나 matching되었는지를 고려하여 segment선택에 활용해줍니다. matching이 많이 될수록 query와 관련성이 높은 segment라고 판단할 수 있습니다.
위의 세 방법을 종합한 score는 다음과 같이 정의됩니다.
\[\text{score} = \alpha \cdot \text{score}_v + (1-\alpha) \cdot \text{score}_r + \beta \cdot \log(1+|C|)\]$\alpha$ 와 $\beta$ 는 balancing hyperparameter, $|C|$는 critical keyword가 matching된 갯수를 의미합니다.
위의 Score를 통해서 선정한 Top-k segment가 LLM model에 들어가게 됩니다.
4. Empirical Results
먼저, HiQA에서는 RAG의 평가지표로 RAGAS대신 Log-Rank Index를 제안했습니다. 해당 지표는 RAG algorithm이 얼마나 효율적으로 document ranking을 하는지 측정하기 위한 지표입니다. 먼저, 해당 index가 왜 필요했는지에 대해서 먼저 살펴보겠습니다. 기존에 쓰이던 RAGAS는 RAG의 성능을 자동으로 측정하기 위한 방법으로, RAG에서 생성된 답변이 query에 대해서 얼마나 잘 일치하는지를 LLM(GPT 3.5 turbo-16k)을 통해 평가합니다. 이 때, QA쌍의 품질에 대해서 평가하는 게 main이다 보니까, RAG process가 문서 전반에 걸쳐서 얼마나 효과적으로 정보를 검색하고 통합하는지를 평가하는데 있어서 한계가 있을 수 있습니다.
정리하자면, RAGAS는 LLM에 기반한 metric이다보니, LLM의 자체적 성능에 의해서 noise와 hallucination이 발생할 수 있다는 문제점이 있고, RAG 얼마나 효율적으로 document를 검색하는지 보다는 QA pair에 더 의존한다는 점과 document전반을 아우르는 성능평가보다는 top-k에 치우친 성능평가를 한다는 점에서 Log-Rank Index를 제안했습니다. 수식에 대한 직관적인 설명을 최대한 전달 드리기 위해서 예시를 만들어 보았습니다.
\[S(r_i) = 1 - \frac{\log(1+\gamma(r_i -1))}{\log(1 + \gamma(N-1))}\]- $r_i : i^{\text{th}}$segment의 순위
- $N :$ 전체 문서의 갯수
- $\gamma :$ shape parameter of curve(Increasing $\gamma$ leads to curve dropping faster at high rankings)

$D$는 $d_1$,$d_2$와 같은 segment들의 set이고, $O_i$는 query인 $q_i$와 segment의 set인 D를 RAG System에 넣어주었을 때, segment들을 re-ranking score에 따라서 순차적으로 나열해준 것입니다. $r_i$는 $O_i$라는 list에서 query인 q와 관련이 있는 segment들의 순위를 의미합니다.
이에 대한 예시로 첫번째 query $q_1$과 Document set을 RAG에 넣어준 결과 $O_1$과 같은 ranking이 된 list가 나왔다고 가정해보겠습니다. 그리고, $q_1$과 관련을 갖는 document는 $d_4$라고 가정하겠습니다. $O_1$에서 $d_4$가 rank 1을 가지므로 $r_1$은 1이 되고, 수식에 넣어주면 최종 score는 1이 됩니다. 즉 가질 수 있는 최대의 값이 됩니다.
두 번째 예시로 query $q_2$와 Document set을 RAG에 넣어준 결과 $O_2$와 같은 ranking list가 나왔고, $q_2$와 관련된 segment는 $d_3$,$d_4$,$d_1$이라고 가정하겠습니다. 논문에서는 이렇게 다양한 document가 query와 연관이 있을 때는, 각각의 segment에 대해서 score를 구하고 그것들의 평균이 최종 score가 된다고 했습니다. 이 과정을 따라가보면, $d_3$는 $O_2$에서 2번째에 있기 때문에, $r_1$에는 2가 들어가고, $d_4$는 1번째에 있기 때문에 $r_2$ = 1, 그리고 $d_1$은 3번째에 있기 때문에 $r_3$는 3이 들어가게 됩니다. 결과값은 구하지 않았지만, 1보다는 작게 됩니다. 결과적으로 수식을 통해 RAGAS에서의 한계를 보완한 것을 확인할 수 있었지만, 개인적으로 아쉬운 부분도 있었습니다. 사실 1번 째 예시는 1개의 관련있는 segment가 1순위에 있어서 최고점인 1을 얻을 수 있었습니다. 그런데, 2번 째 예시에서는 3개의 관련있는 segment가 각각 1,2,3으로 rank가 매겨져 있습니다. 저는 예시에서 사실 다양한 segment들 중에서 3개의 segment만이 query와 관련이 있었고, 각각이 1,2,3의 rank를 갖는다는 것은 ranking이 효율적으로 잘 된 것이라고 생각합니다. 또한, LLM이 하나의 relevant한 document를 참고하는 것보다는 다양한 document를 참고하면서 답변을 생성해낼 때 오는 장점도 있을 수 있을 것이라 생각됩니다.
그런데, Log-Rank Index에서는 score가 최고점인 1이 나오기 위해서는 relevant document가 1개일 때만 가능한 시나리오이고, query와 관련있는 document의 숫자가 많아지면 많아질수록 score가 낮아질 수 밖에 없는 구조를 갖고 있습니다. 이 부분에 대해서는 아쉬움이 들었습니다.
MasQA Dataset
기존의 dataset들이 document의 양이 방대하고, 비슷한 document가 많다는 점에서 유발된 한계를 해결하지 못했다는 점에서, 본 논문에서는 MasQA Dataset을 소개했습니다.(사실 제 시선에서는 비슷한 document가 많음으로 유발되는 한계를 피하기 위해 입맛대로 dataset을 구성하진 않았을까 하는 의문이 있습니다.) MasQA Dataset은 다음의 document들로 구성되어 있습니다.
- Technical Manuals from Texas Instruments
- This subset includes 18 PDF files, each approximately 90 pages, featuring a mix of images, text, and tables in multiple languages.
- Technical Manuals from Chipanalog
- It consists of 88 PDF files, around 20 pages each, presented in a twocolumn format, enriched with images, text, and tables.
- A College Textbook
- A comprehensive 660-page book encompassing images, text, formulas, and tables.
- Public Financial Reports Listed Companies
- This consists of 8 reports for 2023, each report spans roughly 200 pages, mainly including text and tables.
HiQA의 퍼포먼스는 아래와 같습니다.
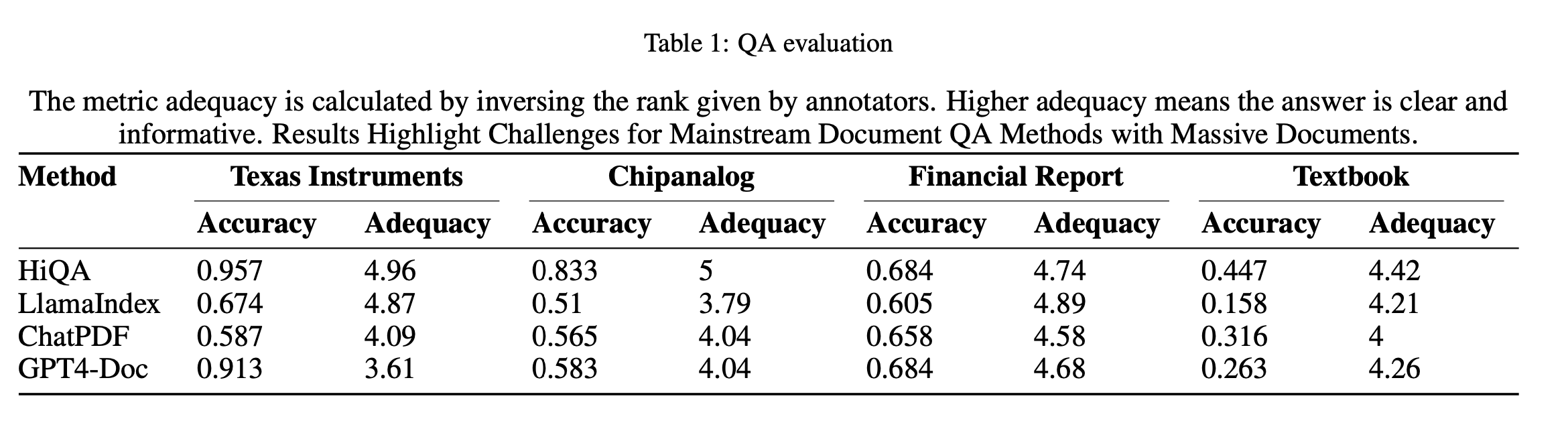
이제 QA Evaluation에 대해서 살펴보겠습니다. 먼저 adequacy는 답변이 얼마나 깔끔하고 정보를 풍부하게 담고있는지를 보여주는 지표라고 합니다. 결과를 보았을 때, HiQA가 LlamaIndex나 ChatPDF나 GPT4-Doc에 비해서 4가지 dataset에서 전부 월등했음을 확인할 수 있습니다.
Text, Image, Table 그리고 formula를 담고있는 데이터셋에서 더 높은 정확성을 보였다는 것은 HiQA에서 목표로 하고자 한 결과에 도달했다고 할 수 있습니다. 한 가지 아쉬운 점은 dataset에 text로만 이루어진 document도 들어갔으면 더 좋지 않았을까 하는 생각이 있습니다.
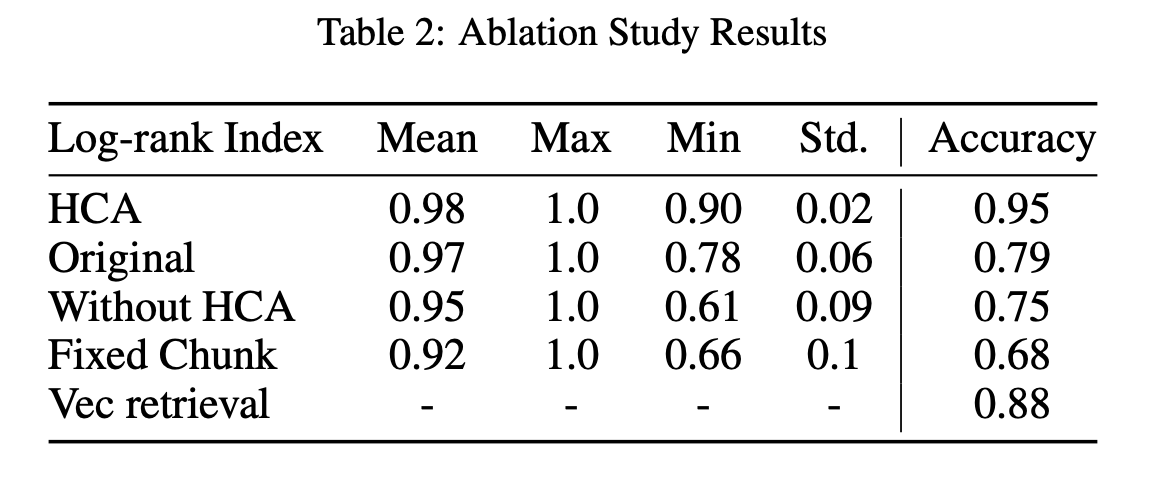
또한 Log-rank Index를 통해서 논문에서 제시한 module들이 정말로 효율적으로 document를 ranking하는 것에 도움이 되었는지를 확인했습니다. 순서대로 HiQA framework 그 자체, cascading을 안 한 경우, HCA module을 뺀 경우, MF와 HCA를 뺀 경우, 그리고 HiQA를 사용하지 않은 경우입니다. 결과적으로 HiQA framework하에서 각각의 module들이 의미가 있었으며, HiQA를 사용한 경우에 Log-index의 평균값도 높으며 standard deviation도 낮아 안정적이고 효율적으로 document ranking을 한다는 것을 알 수 있습니다.
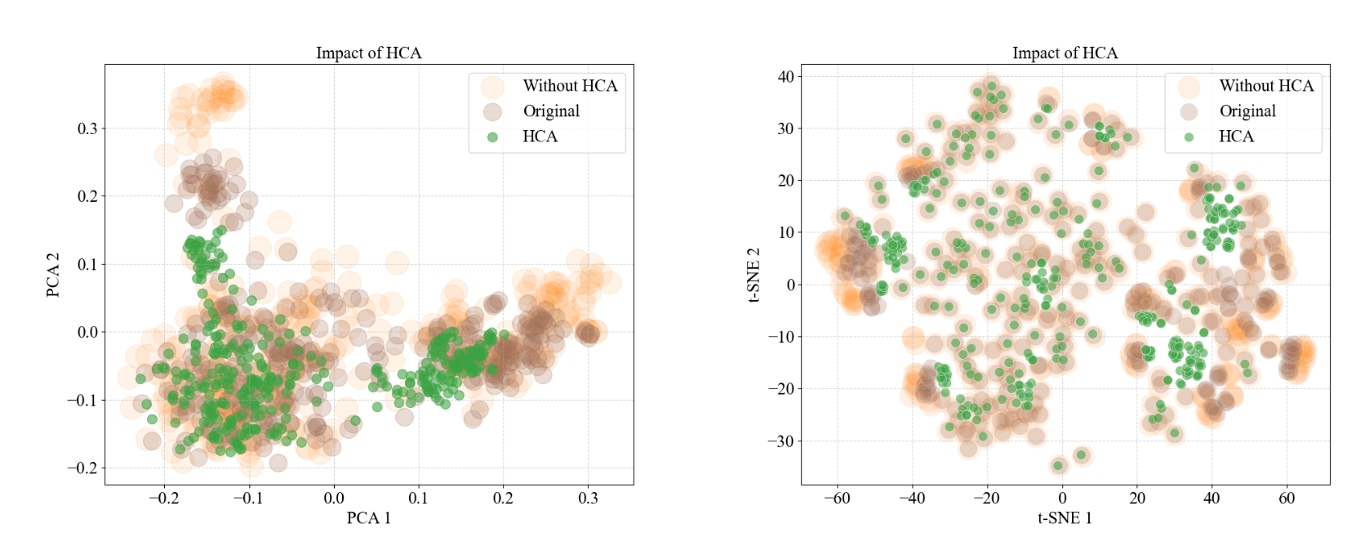
본 논문에서 PCA랑 tSNE(t-districuted stochastic neighbor embedding)을 통해서 이론적인 분석을 하고자 했습니다. PCA와 tSNE는 모두 차원을 축소하는 기법인데요. 차원을 축소하는 이유는 고차원 공간에서는 feature들 간의 관계를 파악하기 어렵거나 분포를 확인하기 어렵다는 일종의 차원의 저주를 해소하고자 하는 목적에서 차원 축소를 할 수 있습니다. PCA는 데이터들로 matrix를 구성하고, 해당 matrix에 대해서 eigen decomposition을 하면 eigen value와 eigen vector를 얻을 수 있게 되는데요, 2차원 평면으로 차원을 축소하고자 한다면, eigen value가 가장 큰 2개와 그에 대응되는 eigen vector를 선택하고 해당 vector들이 span한 공간에 projection을 하는 방식으로 차원축소가 가능합니다. tSNE또한 고차원의 복잡한 데이터를 낮은 차원으로 축소하여 시각적으로 데이터들의 구조를 파악하기 위함입니다. 특히 student-t분포의 특징을 이용하여 데이터 사이의 거리가 가까울 수록 유사도가 크고, 멀수록 유사도가 작아지는 방식으로 차원을 축소시키게 됩니다. Single Document 내부에 있던 segment들의 분포를 가시화하기 위해 PCA로 embedding이 되어있는 document의 segment들을 2차원 평면에 projection을 했더니, HCA module이 있는 경우에 분포가 더욱 잘 뭉쳐져있는 형태라는 것을 확인했습니다. tSNE에서도 마찬가지로 HCA가 있는 경우에 분포가 더욱 응집력이 있다는 것을 확인할 수 있습니다. 분포 내에서 응집력이 있다는 것은 문서 내부의 일관성이 향상되어 중요한 주제나 개념들이 더 명확하게 나타난 것을 의미하고, RAG algorithm이 특정 도메인이나 주제에 관련된 정보를 검색할 때, 더욱 정확하고 관련성이 높은 결과를 도출할 수 있게 됩니다. 또한, 노이즈가 감소한다고 볼 수도 있을 것이고, 관련성이 높은 정보가 잘 구조화 되어있다고 볼 수도 있어서, 필요한 정보를 더욱 빠르게 찾아내어 활용할 수 있게 됩니다.
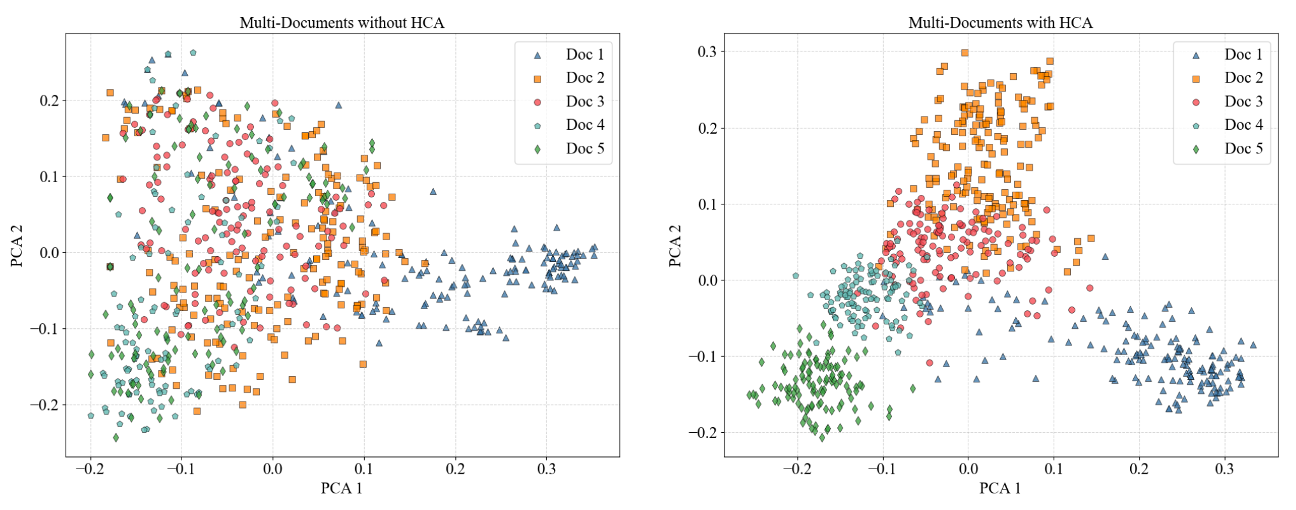
Multi Document인 경우에도 마찬가지로 PCA를 이용해 document들의 분포를 확인했습니다. 결과적으로 HCA module이 있는 경우에 각 document들 끼리 clustering이 되어있는 것을 확인할 수 있습니다. 이는 document들 사이의 관계성을 충분히 고려했다는 것을 의미합니다.
즉, HCA module은 document들 끼리의 관계성도 고려를 할 수 있게 해주었고, single document내부에서도 구조화된 정보를 잘 활용할 수 있게 해주었다고 해석할 수 있습니다.
개인적인 의견으로는 Document를 처리하는 발상이 기발했던 논문이라고 생각합니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.