Paper Review - [EMNLP-Findings 2023] "Enhancing Abstractiveness of Summarization Models through Calibrated Distillation" by Hwanjun Song et al., Dec 2023
Conference : EMNLP-Findings (Conference on Empirical Methods in Natural Language Processing), 2023
1. Contributions
기존의 LLM은 Summarization을 포함해 다양한 task에서 훌륭한 성능을 보여주었습니다. 그러나, Model이 너무 무거워 추론을 하는 데에 많은 시간을 소요한다는 문제점이 있었습니다. 이와 관련해 Sequence-level knowledge distillation은 Seq2Seq model을 경량화하여 더욱 효율적으로 요약문을 생성할 수 있도록 했습니다. 이러한 방법 또한 Loss of abstractiveness(새로운 문장으로 요약하는 것이 아닌, 원문의 문장을 그대로 가져오는 문제)가 발생하게 되었습니다. 본 논문에서는 위와 같은 문제를 해결하는 새로운 방식을 제시했습니다. 논문의 핵심 기여는 다음과 같습니다.
- 1-1. 지금의 Sequence-level distillation이 abstractiveness를 줄이는 문제를 지적했습니다.
- 1-2. 요약문을 생성할 때, Informativeness를 잃지 않으면서 Abstractiveness의 수준을 개선했습니다.
- 1-3. 논문에서 제안된 DisCal이 기존의 SOTA model들의 성능을 뛰어넘었습니다.
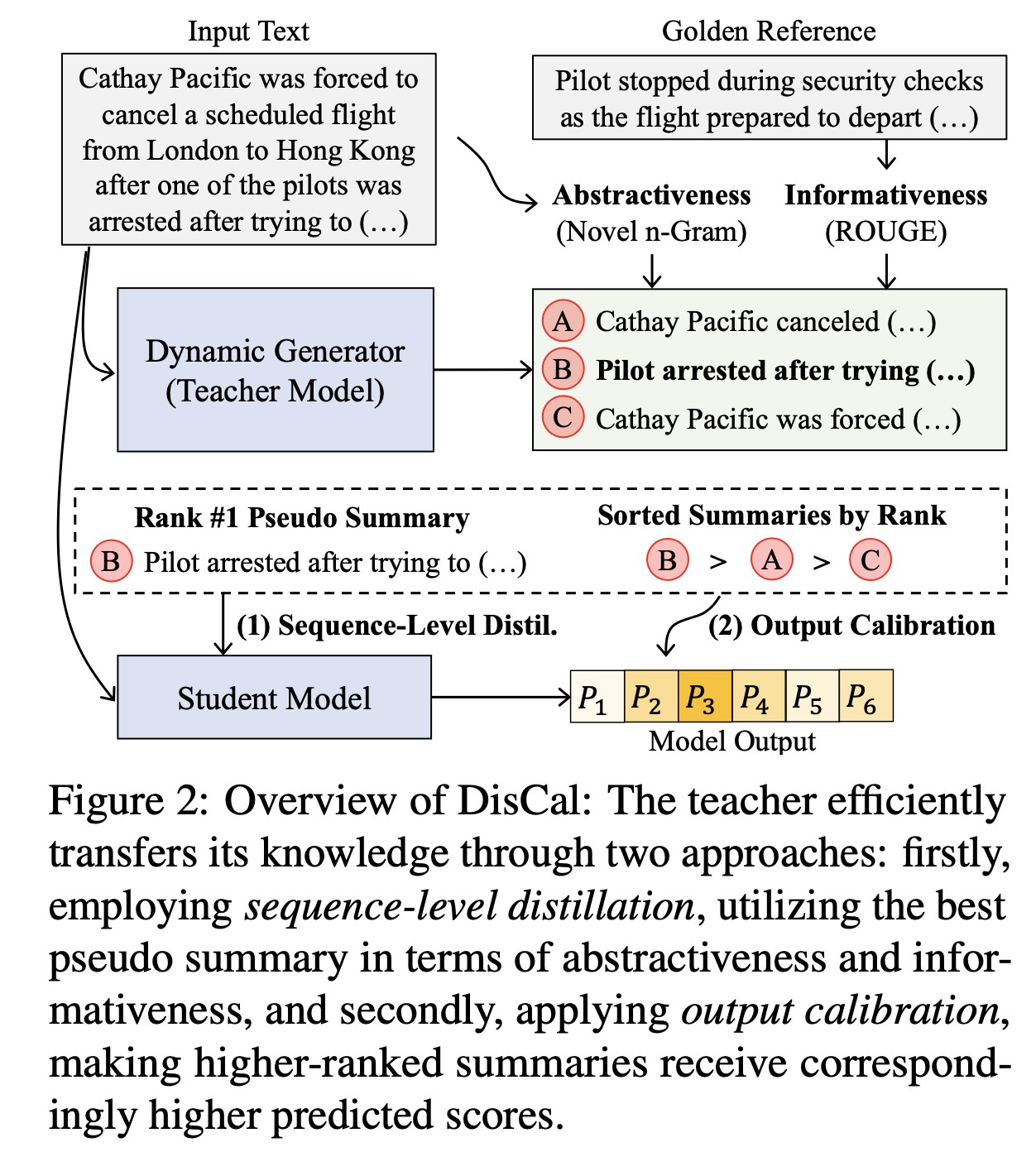
위의 Contribution이 집약되어있는 Figure를 먼저 확인해보겠습니다.

Figure에서 확인할 수 있듯이 원문의 내용을 그대로 가져오지 않으면서 중요한 정보를 담고있고 잘 요약되어있는 것을 확인할 수있습니다.
2. Backgrounds
2-1. ROUGE Score
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score는 자동 요약이나 기계 번역의 품질을 평가하는 데 사용되는 지표입니다. 이 방법은 Generated summary이나 번역문을 사람이 작성한 Reference summary나 번역문과 비교하여, 얼마나 유사한지를 측정합니다. ROUGE 점수는 여러 가지 버전(ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S, ROUGE-SU, ROUGE-N-precision, ROUGE-N-f1)으로 제공되며, 각각 다른 측정 방식을 사용합니다. 여기서는 ROUGE-N과 ROUGE-L에 대해서만 살펴보겠습니다.
- 2-1-1. ROUGE-N
ROUGE-N은 Generated summary와 Reference summary간의 N-gram 오버랩을 측정합니다. 여기서 N은 연속적인 단어의 수를 의미합니다. ROUGE-N의 계산은 다음과 같이 이루어집니다.
\[\text{ROUGE-N} = \frac{\sum_{S \in \{\text{Reference summaries}\}} \sum_{\text{gram}_n \in S} \text{Count}_{\text{match}}(\text{gram}_n)}{\sum_{S \in \{\text{Reference summaries}\}} \sum_{\text{gram}_n \in S} \text{Count}(\text{gram}_n)}\]여기서 \(\text{Count}_{\text{match}}(\text{gram}_n)\)은 Generated summary에서 Reference summary과 일치하는 N-gram의 수를 나타내고, $\text{Count}_(\text{gram}_n)$은 Reference summary 내의 N-gram의 총 수를 나타냅니다. 이 공식은 주로 재현율(recall)에 초점을 맞추고 있지만, 정밀도(precision)와 F1 점수를 계산하는 데에도 사용될 수 있습니다.
- 2-1-2. ROUGE-L
ROUGE-L은 Generated summary와 Reference summary간의 가장 긴 공통 부분 수열(Longest Common Subsequence, LCS)을 기반으로 평가합니다. LCS는 단어의 순서를 유지하면서 두 요약 간에 공통적으로 나타나는 최장의 단어 수열을 찾는 것입니다. ROUGE-L의 계산은 다음과 같습니다.
\[\text{ROUGE-L} = \frac{\text{LCS}(S, \text{Generated Summary})}{|S|}\]여기서 $\text{LCS}(S, \text{Generated Summary})$는 Reference summary $S$와 Generated summary 간의 LCS 길이를 나타내며, $|S|$는 Reference summary의 길이입니다. ROUGE-L 점수는 Generated summary가 Reference summary의 중요한 내용을 얼마나 잘 포함하고 있는지, 그리고 단어의 순서가 얼마나 잘 유지되고 있는지를 종합적으로 반영합니다.
2-2. Novel n-Gram
Novel n-gram은 Generated summary에서 원본 텍스트에는 나타나지 않는 새로운 n-gram의 비율 또는 수를 나타냅니다. 이 지표는 특히 Abstractive summary 작업에서 중요하며, 요약이 단순히 원본 문서에서 문장을 추출하는 것을 넘어 새로운 표현을 생성하는 정도를 평가합니다:
\[\text{Novelty Ratio} = \frac{\text{Generated summary에서 Novel n-gram의 수}}{\text{Generated summary에서 n-gram의 총 수}}\]이 지표는 요약 과정에서의 혁신 정도를 측정하며, 모델이 원본 문서의 내용을 단순 재구성하는 것을 넘어 새로운 방식으로 정보를 전달하도록 장려합니다.
2-3. Seq2Seq Abstractive Summarization
Abstractive Summarization은 앞서 얘기했듯이, 주어진 document나 text를 새로운 구나 문장으로 간결한 요약문을 생성하는 것을 의미합니다. 즉, 원본 데이터에 없는 표현을 형성하는 것이 중요합니다. 관련된 내용을 수식으로 살펴보겠습니다.
먼저, \(X = \{x_1, x_2, \ldots, x_{|X|}\}\)는 주어진 document이고 \(Y = \{y_1, y_2, \ldots, y_{|X|}\}\)는 모델이 생성해내는 요약문이라고 하겠습니다. 이 때, Seq2Seq Transformer는 다음의 식을 $\theta$의 관점에서 극대화하는 것을 목표로 합니다.
\[P(Y|X;\theta) = \prod_{t=1}^{|Y|} P(y_t |Y_{<t}, X; \theta)\]위의 목표를 달성하기 위해서 각각의 input document $X$와 gold summary $Y^*$쌍을 NLL(Negative log-likelihood loss)을 Minimize하는 방식으로 학습을 진행합니다.
\[l_{\text{NLL}}(X, Y^*) = - \frac{1}{|Y^*|}\sum_{t=1}^{|Y^*|} \text{log}P(y_{t}^*|X,Y_{<t}^*;\theta)\]2-4. Sequence-level Knowledge Distillation
Sequence-level Knowledge Distillation은 Teacher model \(\theta_t\)와 Student model \(\theta_s\)가 있다고 할 때, Teacher model의 출력을 Target으로 활용하여 Student model을 학습하는 것을 말합니다. 사전에 학습된 teacher model $\theta_t$가 Pseudo summary \(\tilde{Y} = \{\tilde{y_{1}}, \tilde{y_2},\ldots, \tilde{y}_{|\tilde{Y}|}\}\)를 생성해내면, student model은 $\tilde{Y}$를 target으로 하여, $l_{\text{NLL}}(X,\tilde{Y})$를 최소화하는 방식으로 학습하게 됩니다.
이러한 접근 방식의 장점은 다음과 같습니다:
- 데이터 효율성: Teacher 모델이 생성한 데이터를 활용함으로써, 학습에 필요한 Labeling된 데이터의 양을 줄일 수 있습니다. 이는 특히 Labeling비용이 높거나 Labeling된 데이터가 부족한 상황에서 유용합니다.
- 정규화 효과: Teacher 모델의 출력을 학습 목표로 사용함으로써, student 모델이 teacher 모델의 지식을 흡수하고, overfitting을 방지하는 효과가 있습니다. Teacher 모델이 가지고 있는 지식을 student 모델에 전달함으로써, student 모델이 더 일반화된 지식을 학습할 수 있게 됩니다.
- 성능 향상: Teacher 모델이 높은 성능을 가진 경우, 그 지식을 student 모델에 전달함으로써 student 모델의 성능을 향상시킬 수 있습니다. 특히, teacher 모델이 복잡하고 큰 구조를 가지며 높은 성능을 보이는 경우, 상대적으로 간단한 구조의 student 모델도 teacher 모델의 출력을 통해 높은 성능을 달성할 수 있습니다.
이러한 방법을 통해, student 모델은 teacher 모델의 복잡성을 직접 모델링하지 않고도, teacher 모델의 지식을 효과적으로 흡수할 수 있으며, 이는 모델의 성능 향상과 더불어 학습 및 추론 시간의 효율성을 증가시킬 수 있습니다.
3. Methodology
본 논문에서는 Sequence-level Knowledge distillation은 학습된 teacher model로부터 생성된 하나의 pseudo-summary만을 이용한다고 합니다. 이는 Student model이 다양한 summary를 접하는 데에 대한 제약으로 작동하게 됩니다. 이러한 제약은 Abstractiveness를 줄이게 되며, student model이 생성해낸 예측에 지나친 확신을 갖게 만든다고 합니다.
3-1. Dynamic Summary Generator
위에서의 문제를 해결하기 위해서 논문에서는 teacher model로 Dynamic summary generator를 이용했습니다. 이는 다양한 beam search와 무작위로 Attention mechanism을 Re-scaling하면서 다양한 pseudo summary를 만들게 되었다고 합니다.
Randomly re-scaling attention은 다음과 같은 방식으로 되었습니다.
\[\text{Attention}(Q,K,V) = \text{Softmax}(\frac{QK^T}{k \sqrt{d}})V\]- $k$ is randomly drawn re-scaling factor from the uniform distribution $U(1, \gamma)$
- $\gamma$ is the maximum value for re-scaling
→ 위의 Re-scaling attention방식을 통해서 똑같은 문서임에도 다른 summary를 생성할 수 있게 되었습니다.
3-2. Calibrated distillation
논문에서 소개한 Calibrated distillation은 2가지 측면에서 기존의 sequence-level distillation과 차이가 있습니다.
3-2-1. Gold summary를 pseudo-summary $\tilde{Y}$에서 가장 신뢰할만한 것을 추출하기 위해 이용했습니다.
3-2-2. Student model의 출력이 informative하고 abstractive하도록 Calibrate했습니다.
DisCal에서는 n개의 summary들을 ROUGE와 novel n-gram을 통해서 scoring했습니다. 이는 다음과 같은 수식으로 진행되었습니다.
\(\tilde{Y} = {\{\tilde{y_{1}}, \tilde{y_2}, \ldots, \tilde{y}_{|\tilde{Y}|}\}}\) input으로부터 얻어낸 n개의 pseudo summary.
$s_{\text{info}}(\tilde{Y}_i) :$ $i$ 번째 pseudo summary에 대한 ROUGE-1, ROUGE-2, ROUGE-L의 평균, informative score
$s_{\text{abs}}(\tilde{Y}_i) :$ $i$ 번째 pseudo summary에 대한 novel 1-gram, 3-gram, 5-gram의 평균, abstractiveness score
$s_{\text{calib}}(\tilde{Y}_i) :$ Calibration Score
$\lambda :$ Adjusting the importance of the two factors, balancing term.
\[s_{\text{Calib}}(\tilde{Y}_i) = (1-\lambda)\ \bar{s}_{\text{info}}(\tilde{Y}_i) + \lambda\ \bar{s}_{\text{abs}}(\tilde{Y}_i)\] \[s.t. \ \ \bar{s}_{\text{info}}(\tilde{Y}_i) = s_{\text{info}}(\tilde{Y}_i) / \sum_{j=1}^n s_{\text{info}(\tilde{Y}_j)}\] \[\text{and} \ \ \bar{s}_{\text{abs}}(\tilde{Y}_i) = s_{\text{abs}}(\tilde{Y}_i) / \sum_{j=1}^n s_{\text{abs}(\tilde{Y}_j)}\]위의 방법들을 적용하여,
새로운 ranked pseudo summary \(\tilde{Y}' = \{Y_1', Y_2', \ldots, Y_n'\} \ \ \text{s.t.} \ \forall_{i<j}s_{\text{calib}}(Y_i)' < s_{\text{calib}}(Y_j')\) 을 얻을 수 있게 됩니다. 위의 새로운 summary list를 이용하여 calibrated knowledge distillation을 진행하게 됩니다. 위의 List에서 $Y_n’$이 가장 높은 calibration score를 받은 것이기 때문에, 이를 target summary로 이용하여 student model을 학습시킵니다. 즉, $l_{\text{NLL}}(X, Y_{n}’)$을 최소화시키는 방식으로 knowledge distillation을 진행하게 되는데, 앞에서의 과정을 통해서 Novel n-gram뿐만 아니라, ROUGE Score를 함께 고려할 수 있게 되었습니다. 이는 선택된 summary가 high informative하도록 만들어주었습니다.
마지막으로 $\tilde{Y}’$는 score에 따라 ranking이 되어있는 상태이므로, 이러한 정보를 Student model이 Rank가 높은 Summary에 대해서 높은 확률을 부여하는 방식으로 이용했습니다. 수식은 다음과 같습니다.
\[f(\tilde{Y}) = \frac{1}{|\tilde{Y}|^\alpha}\sum_{t=1}^{|Y|}\text{log}P(\tilde{y}_t | X, \tilde{Y}_{<t};\theta_{s})\]- $\alpha :$ length penalty hyper parameter similarly used for beam search
또한, 다음과 같은 margin based pairwise ranking loss를 이용하여 최종적인 loss function을 구성했습니다.
\[l_{\text{Calib}}(X,\tilde{Y}') = \sum_{i<j}\text{max}(0, f(\tilde{Y}_j) - f(\tilde{Y}_i)+m_{ij})\]- $m_{ij} = (j-i)*m :$ Margin multiplied by the difference in rank between two pseudo summaries.
최종적인 loss function은 다음과 같습니다.
\[l_{\text{DisCal}} = \eta*l_{\text{NLL}}(X,Y_{n}') + l_{\text{Calib}}(X,\tilde{Y})\]- $l_{\text{NLL}}(X,Y_{n}’)$ : Seq-level KD
- $l_{\text{Calib}}(X,\tilde{Y})$ : Output Calib
- $\eta$ is the weight for the NLL loss
4. Empirical Results
본 논문은 DisCal의 성능을 평가하기 위해서 2개의 News summarization dataset인 CNN/DailyMaild과 XSUM을 사용했으며, 1개의 Dialogue summarization dataset인 SAMSum을 사용했습니다.

Teacher model로는 BART를 사용했으며, Student model로는 decoder layer가 다른 BART 12-6 과 BART 12-3을 사용했습니다.
논문에서의 결과는 다음과 같습니다.
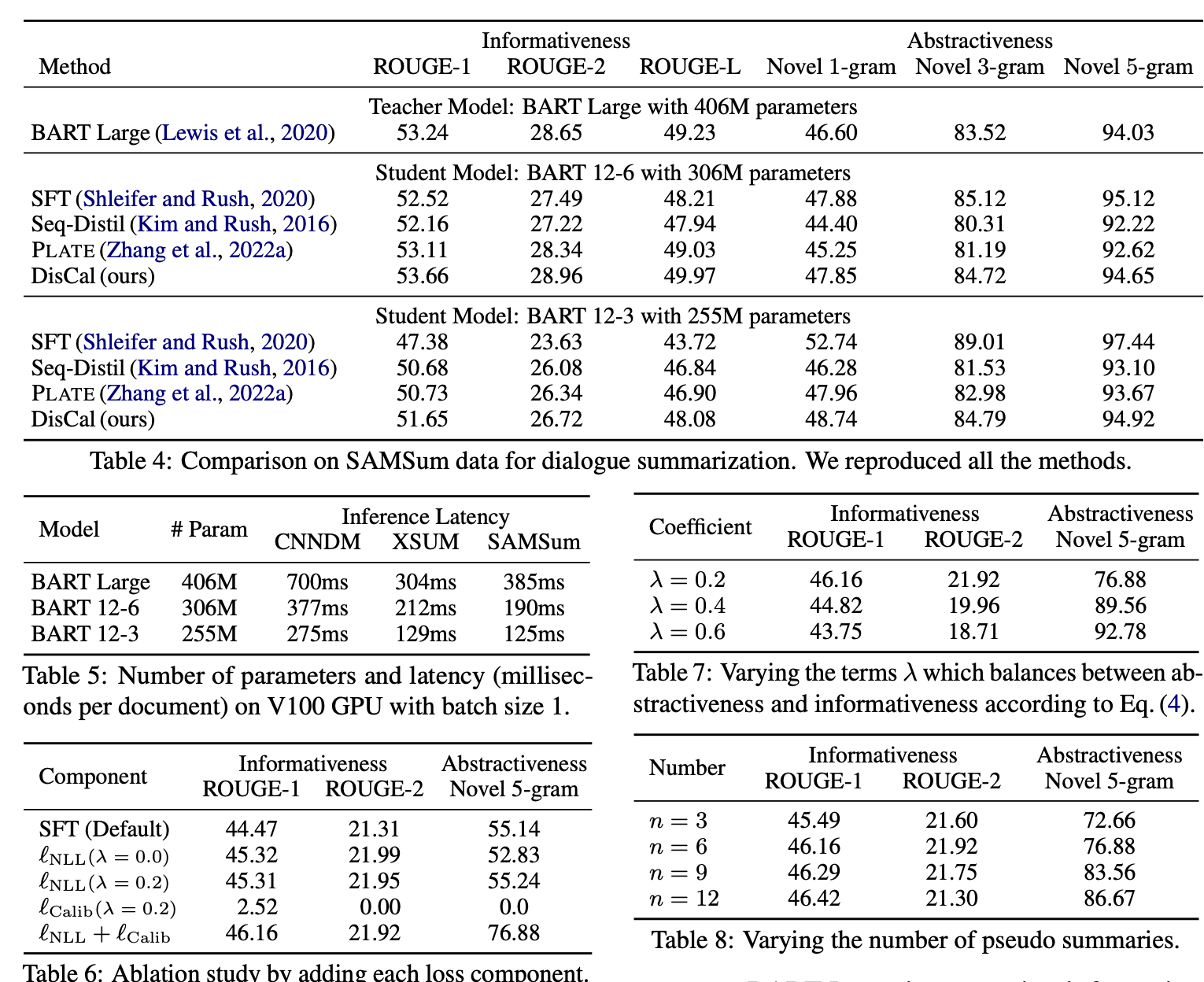
- 성능 : DisCal은 ROUGE 점수와 새로운 n-gram 점수에서 기존의 teacher 모델보다 높은 성능을 보여주며, 특히 BART 12-6 모델을 사용할 때 더욱 그러합니다.
- 추론 지연 시간 : decoder 계층의 수를 줄임으로써, BART 모델의 파라미터 크기와 추론 지연 시간이 감소합니다. BART 12-6과 BART 12-3 모델은 BART Large 모델보다 각각 최대 2.03배와 3.08배 빠른 추론 속도를 달성합니다.
- 사람과 유사한 평가 : GPT-4를 사용한 G-EVAL 평가 방법을 통해, DisCal을 포함한 distillation 모델이 consistency, coherence, relevance, fluency측면에서 사람과 유사한 평가 결과를 보여줍니다. DisCal은 특히 추상성을 향상시키면서 높은 일관성을 유지합니다.
- Paraphrasing과 비교 : 영어-독일어-영어로의 역번역을 통해 요약의 Abstractiveness을 향상시키는 방법보다 DisCal이 Informativeness와 Abstractiveness 사이에 더 유리한 균형을 제공합니다.

사진에서 확인할 수 있듯이, 전반적으로 DisCal은 요약 생성에서 Informativeness와 Abstractiveness을 모두 향상시키는 효과적인 distillation 접근 방식으로, 모델의 성능과 효율성을 동시에 증가시키는 것으로 나타났습니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.