Paper Review - "CHAIN-OF-NOTE ; ENHANCING ROBUSTNESS IN RETRIEVAL-AUGMENTED LANGUAGE MODELS", Wenhao Yu et al., Nov 2023
arXiv, Nov 2023
1. Contributions
RAG Syetem은 retriever가 irrelevant document를 검색해오게 되면 LLM자체에 학습되어있는 parameter들로 충분히 올바른 답변을 할 수 있었음에도 불구하고 잘못된 답변을 생성해낼 수 있다는 문제점이 있습니다. 또한, LLM의 parameter와 retrieved document 모두를 이용해도 답변을 찾을 수 없는 경우에는 ‘unknown’이라고 답변할 수 있어야 합니다. 본 논문에서은 Tencent AI Lab 앞에서의 문제를 해결하기 위해, CHAIN-of-NOTING(CoN)를 소개했습니다. 이를 통한 핵심 기여는 다음과 같습니다.
1-1. Noise Robustness: CoN은 RALMs가 Noise가 많은 문서를 구별하고 무시하도록 하여 robustness를 향상시켰습니다.
1-2. Unknown Robustness: Model이 충분한 지식이 없을 때, “Unknown”으로 응답하는 능력을 향상시킵니다.
1-3. Sequential Reading Notes: Retrieved document에 대해 순차적인 note를 생성하고, 이를 토대로 문서의 관련성을 평가하고 최종 답변에 통합합니다.
위의 기여를 통해서 아래 사진과 같은 답변을 생성할 수 있도록 했습니다.

2. Backgrounds
2-1. Limitations of Retrieval Augmented Language Model(RALM)
RALM은 LLM에 external knowledge를 더해주는 방식으로, Wikipedia와 같은 대규모의 corpus에서 정보를 추출해 적절한 답변을 생성해내는 model입니다. 최근에는 RALM에서 Retriever가 더 적절한 document들을 추출할 수 있도록 하는 연구들이 많이 진행 되었고, 때로는 Noise document가 성능향상에 도움이 될 수 있다는 논문들도 나오고 있습니다. RALM은 다음과 같은 수식으로 표현될 수 있습니다.
\[p(y|x) = \sum_{i} p(y|d_i, x)p(d_i|x)\]$x$ : Input query
$y$ : Model’s generated response
$d_i$ : Retrieved documents(Top-k documents)
위와 같은 RALM의 한계는 다음과 같습니다.
- Risk of Surface-Level Processing : 복잡하고 직관적이지 않은 질문에 대해서는 document나 query의 nuance를 제대로 포착하지 못한 채로, surface-level의 정보에 의존하여 답변을 생성할 수 있습니다.
- Difficulty in Handling Contradictory Information : Document 내에 모순되는 정보들이 있을 때, 어떤 정보가 맞는 정보인지 판단하는 데에 어려움이 있습니다.
- Reduced Transparency and Interpretability : Retriever를 통해서 얻은 정보를 곧바로 Generator에 보내게 되면서 어떻게 답변이 생성된 것인지에 대한 통찰이 어렵게 됩니다.
- Overdependence on Retrieved Documents : LLM에 학습되어있는 data보다 Document로부터 추출한 정보에 많이 의존하게 되며, document에 noise가 있는 경우에 문제가 발생하게 됩니다.
위와 같은 문제점들을 해결하기 위해서, 본 논문에서는 ‘CHAIN-of-NOTE’라는 framework를 제안했습니다.

2-2. EM score(Exact Match Score)
EM score(Exact Match Score)는 QA System에서 model의 성능을 평가하는 데 사용되는 지표 중 하나입니다. EM score는 model이 생성한 답변이 실제 정답과 완전히 일치할 때만 점수를 부여합니다. 즉, model의 답변과 정답이 문자 그대로 완전히 동일할 경우에만 ‘Exact Match’로 간주하여 score를 받게 됩니다.
이 지표는 model이 주어진 질문에 대해 얼마나 정확한 답변을 제공할 수 있는지를 직접적으로 측정하는 방법으로 사용됩니다. 예를 들어, query에 대한 정답이 “paris”인 경우, model이 “paris”라고 정확히 답변해야 EM 점수를 얻을 수 있습니다. 만약 model이 “Capital of France”와 같이 의미는 동일하지만 표현이 다른 답변을 제공한다면, EM score는 부여되지 않습니다.
EM 점수의 주요 장점 중 하나는 그 명확성에 있습니다. 성능 측정이 직관적이며, model이 제공한 답변이 정답과 얼마나 정확히 일치하는지 바로 알 수 있습니다. 그러나 이 지표는 단점도 가지고 있습니다. 특히, model이 실제로는 올바른 정보를 포함하고 있거나 유사한 의미의 답변을 제공해도, 정확한 문자열 일치가 아니면 인정받지 못한다는 점에서 유연성이 부족합니다. 따라서, EM score 외에도 F1 score와 같은 다른 지표들을 함께 사용하여 모델의 성능을 보다 종합적으로 평가하는 것이 일반적입니다.
3. Methodology
Chain-of-Note의 핵심 idea는 각 document별로 concise and contextually relevant summary(note)를 만들어 활용한다는 점에 있습니다. CoN은 앞서 추출한 Sequential reading notes를 통해서 query와 document사이의 연관성과 document내부에서 가장 관련성이 깊은 정보를 찾아내고, information끼리 모순되는 것을 해소하는 데에 활용했습니다.
CoN의 Mechanism을 살펴보겠습니다. 먼저 Input question $x$와 $k$ derived documents $[d_1, \ldots, d_k]$를 통해서 multiple segments $[y_{d_1}, \ldots, y_{d_k}, y]$를 생성해냅니다. 이 때, $y_{d_i}$는 $d_i$에 대응되는 reading note를 의미합니다. 이를 위해서, CoN은 3가지 key step이 있습니다.
3-1 Notes Design
- Document contains Answer : Model은 해당 정보를 기반으로 최종 응답을 형성합니다.
- Document provides useful context : Document가 직접적인 답변은 아니지만 유용한 맥락을 제공할 경우, model은 이 정보와 내재된 지식을 활용해 답변을 도출합니다.
- Irrelevant document : model이 답변을 제공하기에 충분한 지식이 없을 때, “Unknown”으로 응답합니다.
3-2 Data Collection
ChatGPT를 사용하여 10k의 질문을 NQ training dataset에서 무작위로 sampling하고, 세 가지 노트 생성 유형에 대한 지침과 문맥 예시를 제공합니다. 이 때, 다양한 실제 사용자 query를 포함하는 NQ dataset이 주요 dataset으로 선택되었습니다. 또한, model을 검증하기 위해 TriviaQA, WebQ, RealTimeQA를 포함한 추가 open domain dataset에서도 성능을 테스트합니다.
3-3 Model Training
10K training dataset을 사용하여 CHAIN-OF-NOTE model을 훈련시키는 과정은 LLaMa-2 7B 모델을 기반으로 했습니다.
4. Empirical Results
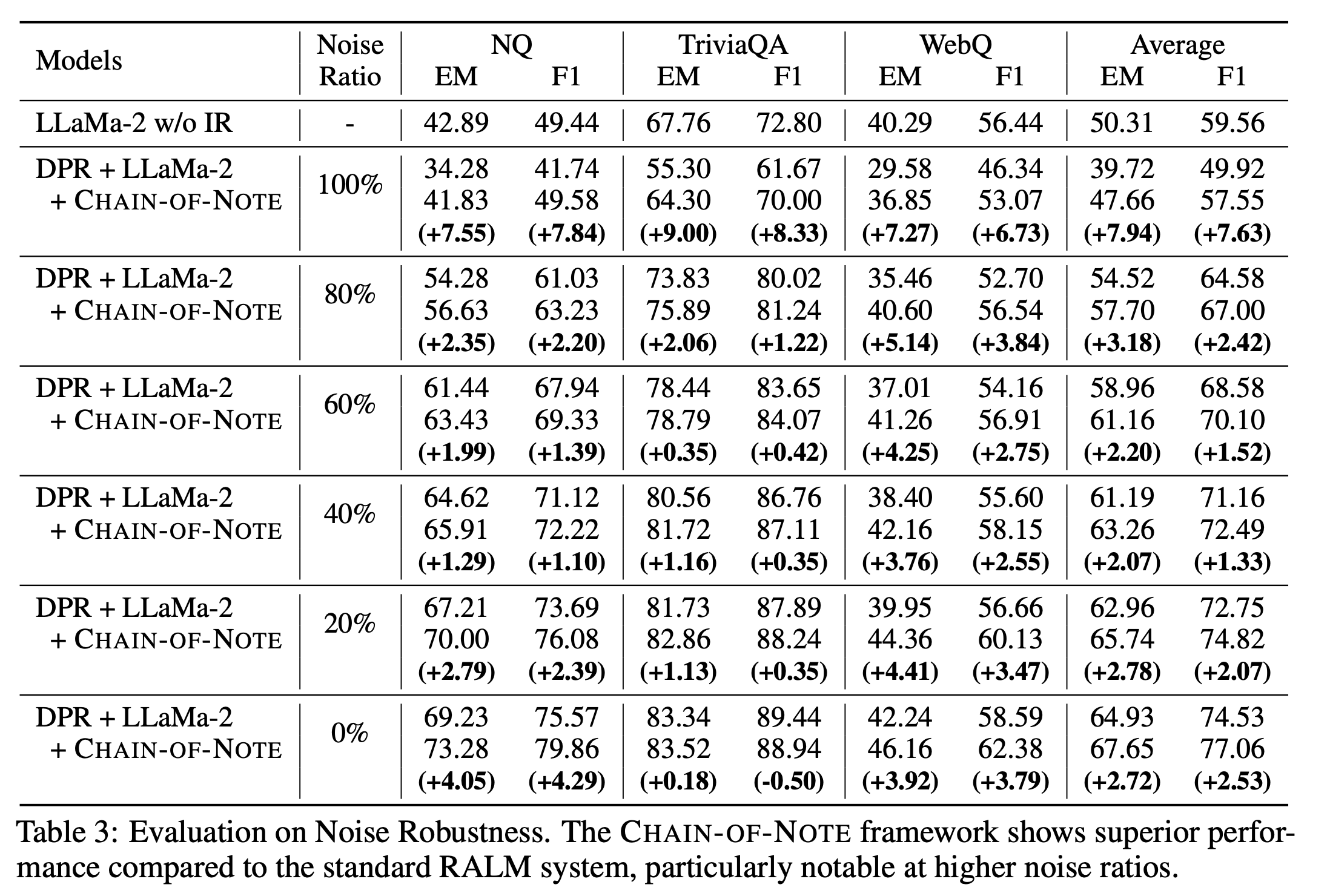
아래의 Table을 통해서 Noise가 증가함에 따라 LLaMa-2 7B에 CoN을 결합한 것이 성능 개선을 더 많이 하고있다는 것을 확인할 수 있습니다. 이는 Noise Robustness가 LLaMa2 7B를 단일로 사용했을 때보다 개선되었다는 점을 의미합니다.
논문에서 제시한 Case study는 아래와 같습니다.

위 사진에서 알 수 있듯이, RALM에서는 document에서 잘못된 정보를 추출하여 오답을 했던 반면에 CoN을 적용한 model에서는 적절한 답변을 찾아낸 것을 확인할 수 있습니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.