Paper Review - [NIPS 2017] "Attention Is All You Need" by Ashish Vaswani et al., 2017
Conference: NIPS (Neural Information Processing Systems), 2017
1. Contributions
NLP분야는 항상 새로운 기술 혁신을 통해 발전해 왔습니다. 최근 몇 년 동안, “Attention Is All You Need”라는 논문은 이 분야에서 가장 혁신적인 발전 중 하나로 널리 인정받고 있습니다. 이 논문은 Ashish Vaswani와 그의 동료들에 의해 2017년 NIPS (Neural Information Processing Systems)에서 발표되었으며, 기존의 NLP model의 한계를 극복하고 새로운 방향을 제시했습니다. 본 논문의 기여는 다음과 같습니다.
1-1. RNN이나 CNN에는 의존하지 않은 Attention mechanism만으로 model의 architecture를 구성한 Transformer model을 소개했습니다.
1-2. Transformer model은 sequence의 각 요소를 동시에 처리할 수 있다는 점에서 순차적으로 처리하던 기존의 RNN을 이용한 model들에 비해서 학습 속도를 크게 향상시켰습니다.
1-3. Positional Encoding이나 Scalar-dot product과 같은 방법론을 토대로 model의 성능을 높일 수 있는 아이디어를 소개했습니다.
2. Backgrounds
2-1. Encoder-Decoder Structure
Encoder-decoder 구조는 주로 Sequence-to-Sequence(Seq2Seq)작업에 사용되는 Neural network architecture입니다. 이 구조는 Encoder와 Decoder로 구성됩니다. Encoder-decoder 구조의 주 목적은 input sequence $x = (x_1, \ldots, x_n)$를 encoding layer를 통과시켜 latent vector $z = (z_1, \ldots, z_n)$으로 encoding한 다음에, 다시 $z$를 decoding layer를 통과시키면서 output sequence $y = (y_1, \ldots, y_n)$로 변환하는 것입니다. 이는 Machine Translation, Automatic Summarization, Speech Recognition, Image Captioning 등 다양한 분야에서 활용됩니다.
- Encoder
Encoder는 Input Sequence를 받아들여 이를 고정된 크기의 context vector나 state로 변환하는 역할을 합니다. 이 context vecotor는 Input sequence의 중요한 정보를 압축하여 담고 있으며, decoder가 output sequence를 생성하는 데 필요한 ‘context’를 제공합니다. Encoder는 일반적으로 RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory), GRU(Gated Recurrent Units)와 같은 순환 신경망 구조 또는 Transformer 모델에서 볼 수 있는 self-attention mechanism을 사용합니다.
- Decoder
Decoder는 Encoder로부터 받은 context vector를 사용하여 output sequence를 단계별로 생성합니다. 각 단계에서, decoder는 이전 단계에서 생성된 output과 context vector를 바탕으로 다음 출력을 예측합니다. Decoder의 구조도 Encoder와 유사하게 RNN, LSTM, GRU 또는 Transformer 등을 사용할 수 있습니다. 특히 본 논문에서는 Decoder의 각 단계에서 Encoder의 전체 Input sequence에 대한 attention mechanism을 적용하여, 출력 생성에 가장 중요한 입력 부분에 더 많은 가중치를 두는 방식으로 architecture를 구성했습니다.
*Context vector : 인코더가 생성한 컨텍스트 벡터는 전체 입력 시퀀스의 정보를 요약한 것으로, 디코더가 출력 시퀀스를 생성하는 데 필수적인 역할을 합니다.
2-2. Feed Forward
Feed Forward Networks는 가장 간단한 형태의 인공 신경망 구조입니다. Transformer 모델에서는 Encoder와 Decoder layer 내에서 핵심적인 역할을 합니다. Transformer의 각 layer에 포함된 feed forward network는 두 개의 선형 변환과 그 사이에 있는 ReLU 활성화 함수를 적용합니다.
- 작동 원리 : Sequence의 각 위치마다 feed forward network는 데이터를 독립적으로 처리합니다. 이는 같은 feed forward network가 sequence의 각 위치에 별도로 그리고 병렬로 적용된다는 의미이며, 이는 model이 sequence를 효율적으로 처리할 수 있게 하는 데 기여합니다.
- 구조: Transformer 내의 feed forward network의 전형적인 구조는 두 개의 affine transformation과 그 사이에 비선형 활성화 함수, 보통 ReLU(Rectified Linear Unit)가 있습니다. 수식으로는 $\text{FFN}(x) = \text{max}(0, x \cdot W_1 + b_1) \cdot W_2 + b_2$ 로 나타낼 수 있으며, 여기서 $W_1, b_1, W_2, b_2$는 Affine transformation의 parameter이고, $\text{max}(0, x)$는 ReLU 함수를 나타냅니다.
- 목적: Transformer 내의 feed forward network의 주된 목적은 multi-head attention mechanism 후 데이터를 처리하고 다음 layer로 전달하기 전에 사용됩니다. 이는 모델이 비선형성을 도입함으로써 더 복잡한 표현을 학습할 수 있게 합니다.
2-3. Layer Normalization
Layer Normalization은 심층 신경망의 학습 과정을 안정화하는 데 사용되는 기술입니다. 이는 feature를 기준으로 input들을 normalization하는데, Transformer와 같이 batch size가 작을 수 있는 모델에서 특히 유용합니다.
- 기능: Layer Normalization은 layer의 모든 입력 합에 대해 각각의 훈련 케이스에서 사용되는 평균과 분산을 계산하여 정규화를 수행합니다. Batch normalization와 다르게, layer normalization은 개별 예시마다 이 작업을 수행하기 때문에, batch size가 작은 NLP 작업에 더 효과적입니다.
- 수식: Layer Normalization의 수식은 $\text{LN}(x) = \frac{(x-\text{mean}(x))}{\sqrt{\text{var(x) + e}}} *\gamma +\beta$로 표현할 수 있으며, 여기서 $x$는 layer로의 input vector, $e$은 수치 안정성을 위해 추가된 작은 상수, 그리고 $\gamma$와 $\beta$는 정규화된 값들을 scaling하고 이동시키기 위한 learnable parameters입니다.
- 이점: Layer Normalization을 적용함으로써, Transformer model은 network 전반에 걸쳐 안정된 활성화 분포를 보장하며, 이는 훈련 과정을 가속화하고 model의 전체적인 성능을 향상시키는 데 기여합니다.
3. Methodology
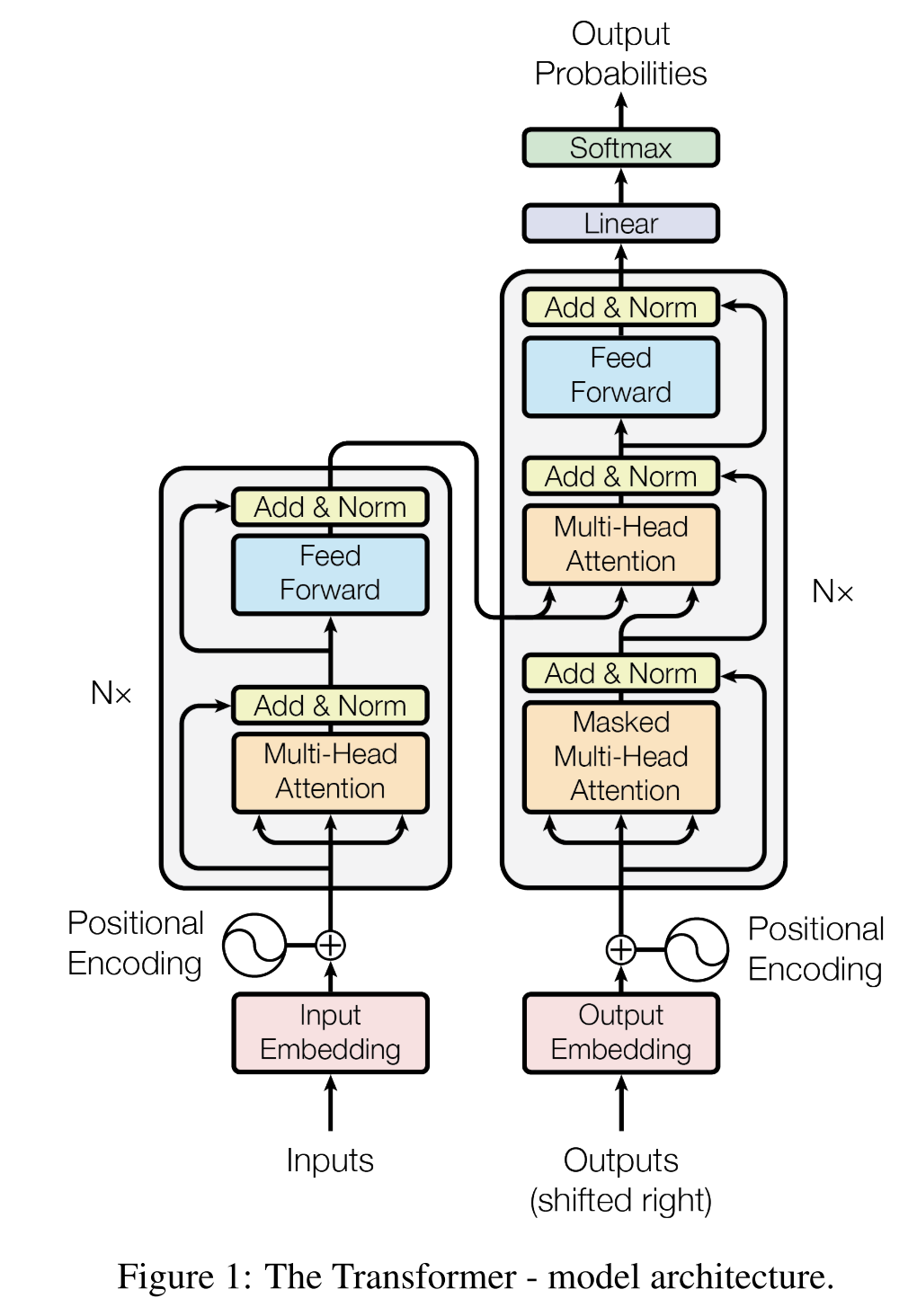
아래의 사진은 Transformer의 Architecture입니다. 큰 박스를 기준으로 본다면 왼쪽에 있는 박스는 Encoder부분이고, 오른쪽에 있는 박스는 Decoder부분입니다. Encoder와 Decoder가 연결되어있는데, 이것을 Encoder-Decoder Network라고 부릅니다. 이제 Architecture를 구성하는 요소들을 하나씩 차근차근 보도록 하겠습니다. 먼저 기본적인 부분들에 대해서는 간략하게 설명하고 넘어가도록 하겠습니다.
- Feed Forward : Affine Layer + Activation Function
- Add & Norm : 이 계층은 Multi-head attention의 output과 그 input을 더한 다음, layer normalization를 적용합니다. 이 과정은 model의 안정성을 유지하고 더 깊은 네트워크 구축을 가능하게 합니다
3-1. Scaled Dot-Product Attention
먼저, Encoder에서 Multi-Head Attention에 해당하는 부분을 살펴보겠습니다.
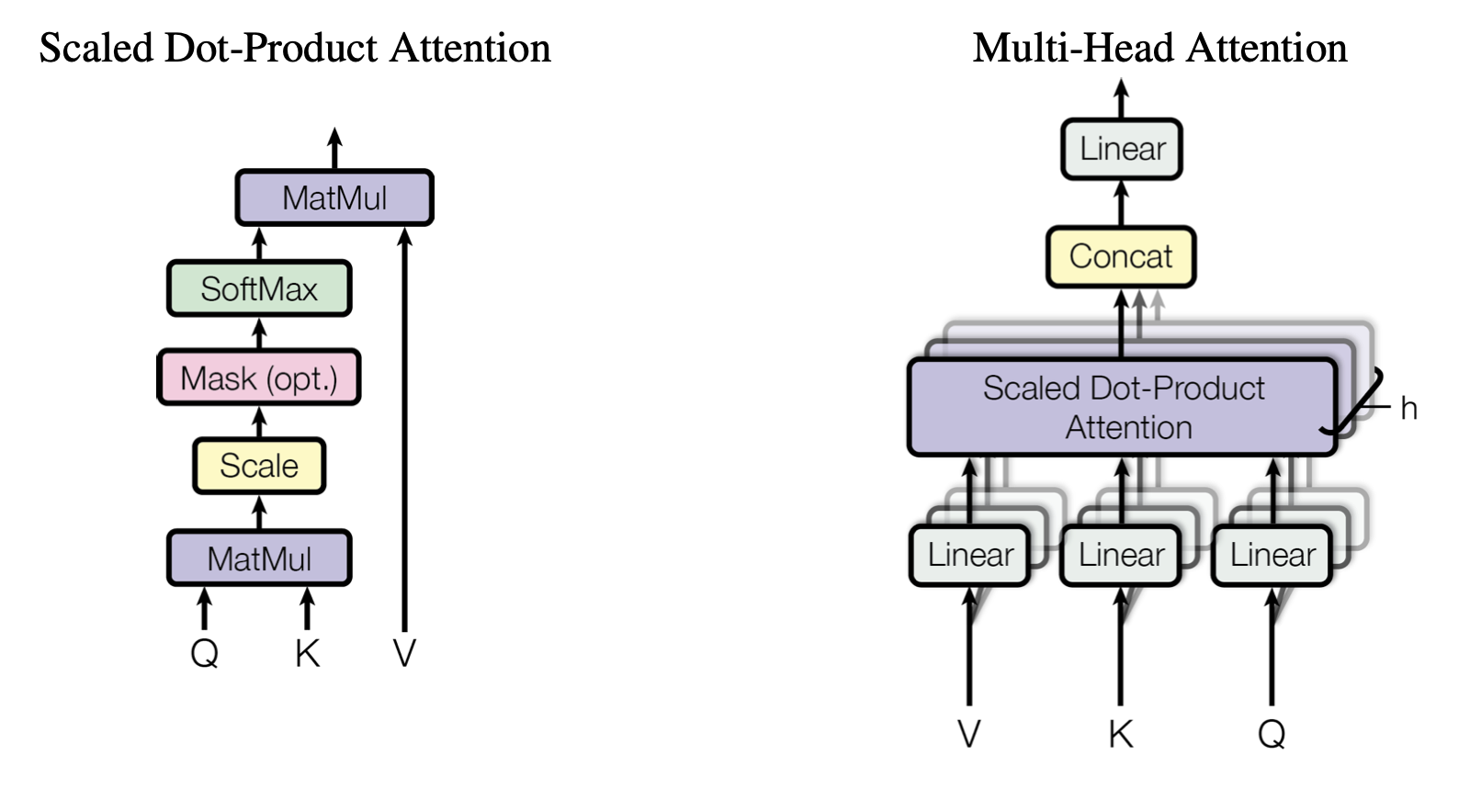
Scaled Dot-Product Attention은 위와 같은 구조를 갖고 있습니다. 위의 구조를 수식으로 한 번에 표현하면 다음과 같이 표현됩니다.
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]- Query ($Q$): 현재 관심을 가지고 있는 특정 위치의 정보를 나타내며, 어떤 정보를 ‘찾고자 하는지’에 대한 표현입니다. Transformer의 Decoder에서는 output sequence를 생성할 때 현재 위치에서 필요한 정보를 ‘질의’하는 역할을 합니다.
- Key ($K$): 비교 대상이 되는 정보의 표현으로, Query가 참조하려는 input sequence 내의 정보를 나타냅니다. 즉, Query가 ‘찾고자 하는 정보’와 어떤 정보가 가장 관련이 있는지를 결정하는 데 사용됩니다.
- Value ($V$): 실제로 Attention mechanism이 가중치를 적용할 때 참조하는 정보의 내용입니다. Key와 연관된 각 위치에서의 정보를 나타내며, Key의 similarity에 따라 가중치가 부여된 후, 이 정보를 통해 최종적으로 Query에 대한 응답을 생성합니다.
$Q$를 기준으로 $K$와의 similarity를 계산한 다음, 이 similarity 점수를 이용하여 입력된 $V$에 대한 가중치를 결정합니다. 구체적으로, $Q$와 $K$의 dot product($QK^T$)은 각 $Q$와 모든 K 사이의 similarity를 계산하며, 이 때 $d_k$의 제곱근으로 나누어주는 scaling 과정을 거치게 됩니다. 이렇게 계산된 similarity score는 softmax function를 통과하여, 각 $K$에 대한 가중치로 변환됩니다. 이 가중치는 결국 $V$에 적용되어, Input sequence에서 각 요소의 중요도에 따라 가중된 평균을 구하는 데 사용됩니다. 결과적으로, Attention 메커니즘은 $Q$의 관점에서 볼 때 중요한 정보를 담고 있는 $V$의 요소에 더 많은 가중치를 부여합니다.
이제부터 이 Attention수식을 하나씩 뜯어보겠습니다. 먼저, $QK^T$ 부분에 담겨있는 직관이 있습니다. K를 전치시킨 것과 $Q$의 inner product을 구해준 것인데, inner product에 담긴 의미를 그림으로 살펴보겠습니다.
다음과 같은 $Q$와 $K$가 있다고 하겠습니다.
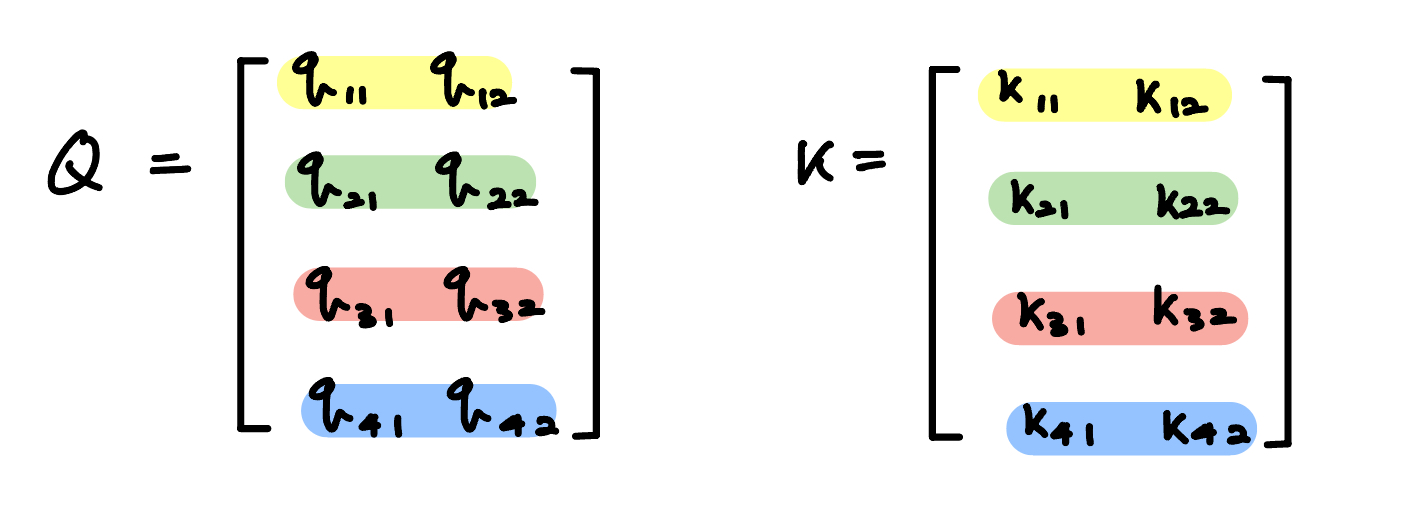
$QK^T$ 총 4 by 4 matrix가 나오게 되는데, 아래의 그림처럼 모든 매칭될 수 있는 케이스에 대해서 고려할 수 있게 해줍니다.
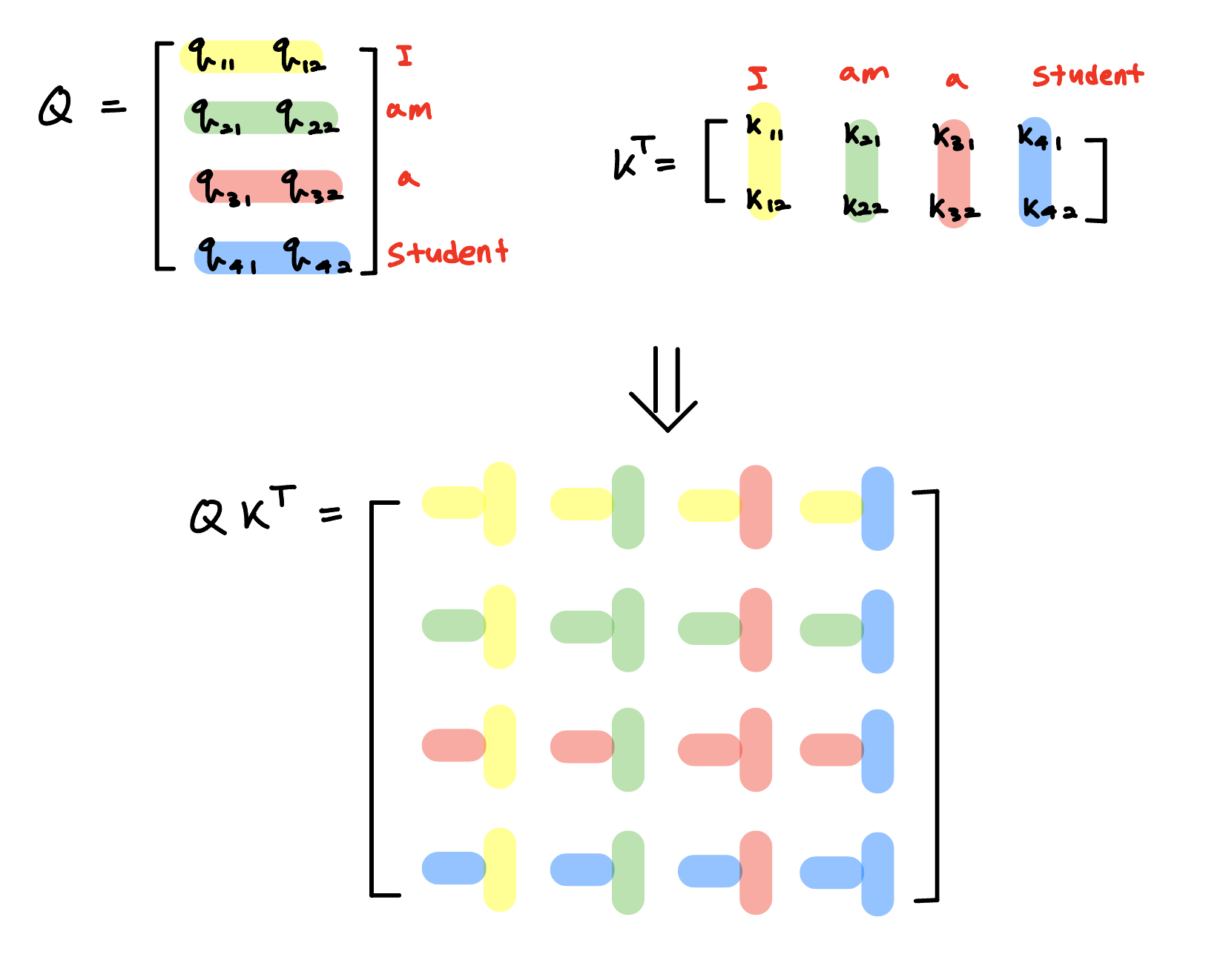
여기서 집중해야할 부분은 바로 inner product입니다. Inner Product은 두 벡터 사이의 similarity을 확인해주는 척도로 쓰일 수 있습니다. 내적의 수식을 보겠습니다.
\[{\vec{a} \cdot \vec{b}} = \cos(\theta) \|\vec{a}\| \|\vec{b}\|\]Inner product의 수식을 잘 보면 $\theta$의 값과 vector $a$와 $b$의 norm에 따라서 inner product의 크기가 달라진다는 것을 알 수 있습니다. 이는 두 벡터의 similarity를 계산할 때, 두 벡터 사이의 각도와 두 벡터의 크기를 고려하여 similarity를 계산한다는 것을 의미합니다. 여기서 중요한 점은 cosine similarity가 각도만을 고려하는 반면, inner product은 벡터의 크기까지 고려한다는 것입니다. 따라서 inner product은 cosine similarity에 비해 더 많은 정보를 제공하여 similarity를 평가할 때 더 유용할 수 있습니다.
결과적으로, Dot product는 벡터의 크기까지 고려해 더 유사한 것에 더 큰 가중치를 주어 Softmax를 통과할 때 더 높은 확률값을 부여하게 된다는 장점이 있습니다. 그러나, Dot product는 때로 매우 큰 값이 나올 수 있다는 단점이 있습니다. 그렇게 되면 값들이 Tractable하지 않을 수가 있어서 Scaling의 필요성이 있습니다.
Attention 논문에서는 K의 dimension인 $d_k$의 제곱근으로 나누어줌으로 해당 문제를 해결했습니다.
요약하자면, Scale-dot product attention은 단어와 단어 내지는 글자와 글자가 얼마나 크게 연관되어있는지 확인해주는 효율적인 방법이라고 볼 수 있습니다.
- Code에서는 Masking이 들어갑니다. 이는 ‘I am a student’가 예문이라고 할 때, 실제 답변을 generate할 때와 ‘I’를 예측하기 위해서 뒤의 ‘am’, ‘a’, ‘student’를 참고하는 것이 불가능하기 때문에 뒤의 ‘am’, ‘a’, ‘student’를 masking해주는 것과 같은 방식으로 적용됩니다.
3-2. Multi-Head Attention
Multi-Head Attention은 CNN에서 feature map과 같은 역할을 한다고 볼 수 있습니다. 즉, Q,K 그리고 V사이의 관계를 포착함에 있어서 최대한 다양한 특징들을 잡아내기 위함이라고 생각할 수 있습니다. 간단한 예문을 통해서 접근해보도록 하겠습니다.
문장: “The cat sat on the mat. It was happy.”
이 문장을 처리하기 위해 2개의 Attention head를 사용하는 Multi-Head Attention을 가정해 보겠습니다.
- Head 1: 문맥적 관계 포착에 집중
- Head 2: 문법적 구조 포착에 집중
Head1의 작동 방식:
Head1은 문맥적 관계, 특히 대명사 “It”과 그 대명사가 가리키는 명사 “cat” 사이의 관계에 주목할 수 있습니다. 이 head는 “It”과 “cat” 사이의 attention score를 높게 할당함으로써, “It”이 “cat”을 참조하고 있음을 model에 알립니다. 이를 통해 model은 문장 내에서 대명사의 참조를 더 잘 이해할 수 있게 됩니다.
Head2의 작동 방식:
Head2는 문법적 구조, 예를 들어 주어(“cat”)와 동사(“sat”) 사이의 관계에 더 집중할 수 있습니다. 이 head는 문장의 동사와 주어 사이의 attention score를 높여, 문장의 문법적 구조를 파악하는 데 도움을 줍니다. 이를 통해 model은 문장의 구문 구조를 더 잘 파악하고, 각 단어의 역할을 이해할 수 있습니다.
실제로 Head들이 정확히 위의 목적(’문맥적 관계’, ‘문법적 구조’)과 일치하도록 작동하는 것은 아닙니다. 그러나, 최대한 Prediction을 잘 할 수 있도록 문장 내의 특성들을 잘 파악하는 방향으로 작동하게 됩니다. Multi-head attention architecture를 볼 때, Q, K, V가 Linear tensor를 통해서 들어가기 때문에, Multi-head attention에 들어가고 scalar-dot product이후에 나온 score를 토대로 model의 loss가 작아지는 방향으로 각각의 head들이 학습됩니다.
3-3. Positional Encoding
Positional Encoding은 input sequence의 각 요소가 문장 내에서 어디에 위치하는지 model에게 알려주기 위해 Positional Encoding을 도입합니다. 이는 각 단어의 위치 정보를 나타내는 vector를 input embedding에 추가하는 방식을 통해서 이루어집니다. Positional Encoding은 특정 패턴(e.g. sin function과 cosine function의 조합)을 사용하여 각 위치에 고유한 값을 할당함으로써, model이 단어의 순서 정보를 학습할 수 있도록 돕습니다.
Positional Encoding의 수학적 표현은 다음과 같습니다:
\[PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}})\] \[PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}})\]여기서 $pos$는 단어의 위치, $i$는 demension of index, $d_{model}$은 dimension of model를 나타냅니다. 이러한 방식으로 각 위치마다 고유한 vector가 생성되며, 이 vector는 input embedding과 합쳐져서 model에 입력됩니다.
Positional Encoding을 통해 Transformer는 sequence 내 각 단어의 상대적 또는 절대적 위치를 고려할 수 있게 되어, 문장의 의미를 더 잘 이해하고 효과적으로 처리할 수 있습니다.
4. Empirical Results
“Attention Is All You Need” 논문에서 제시된 Transformer model의 성능을 평가하기 위해 다양한 실험을 수행하였습니다. Transformer model이 기존의 RNN이나 CNN 기반 model들에 비해 어떤 이점을 제공하는지를 살펴보겠습니다.
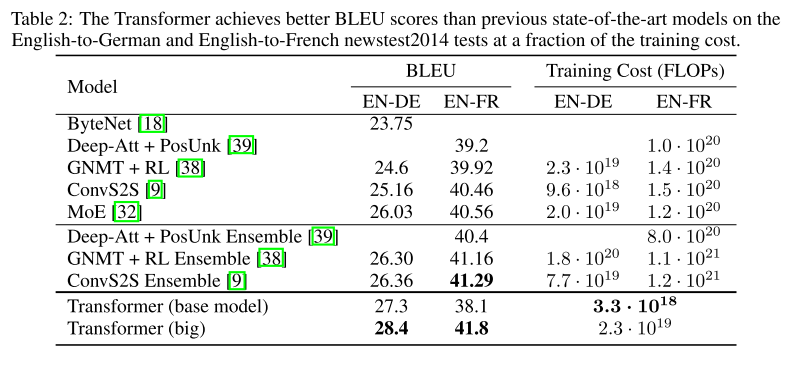
4-1. Machine Translation
Transformer 모델은 주로 Machine Translation task에 적용되었습니다. WMT 2016 영어-독일어 번역 task에서 Transformer는 BLEU 점수 기준으로 당시 최고 성능을 달성하였습니다. 이는 같은 dataset에서 훈련된 기존의 최고 성능 RNN model이나 CNN model들을 상당한 차이로 능가하는 결과였습니다.
- 결과: Transformer model은 영어-독일어 번역에서 28.4 BLEU 점수를 기록했습니다. 이는 이전 모델 대비 약 2점 이상의 개선을 의미합니다.
- 비교: RNN 기반 model과 비교할 때, Transformer는 학습 시간이 현저히 단축되었습니다. 특히, Transformer model은 데이터의 각 요소를 병렬로 처리할 수 있는 구조 덕분에 학습 과정에서의 효율성이 크게 향상되었습니다.
4-2. Model Efficiency and Scalability
Transformer 모델은 효율성과 확장성 면에서도 주목할 만한 결과를 보여주었습니다. Model의 크기와 훈련 데이터의 양을 증가시킬수록 성능이 향상되는 경향을 보였으며, 이는 Transformer의 병렬 처리 능력과 깊은 network 구조가 model의 용량과 학습 효율성을 가능하게 했음을 시사합니다.
- 확장성: 더 큰 model과 더 많은 data를 사용할 때, Transformer는 성능이 비례하여 증가하는 것으로 나타났습니다. 이는 Transformer가 대규모 dataset과 복잡한 언어 task에 효과적으로 적용될 수 있음을 의미합니다.
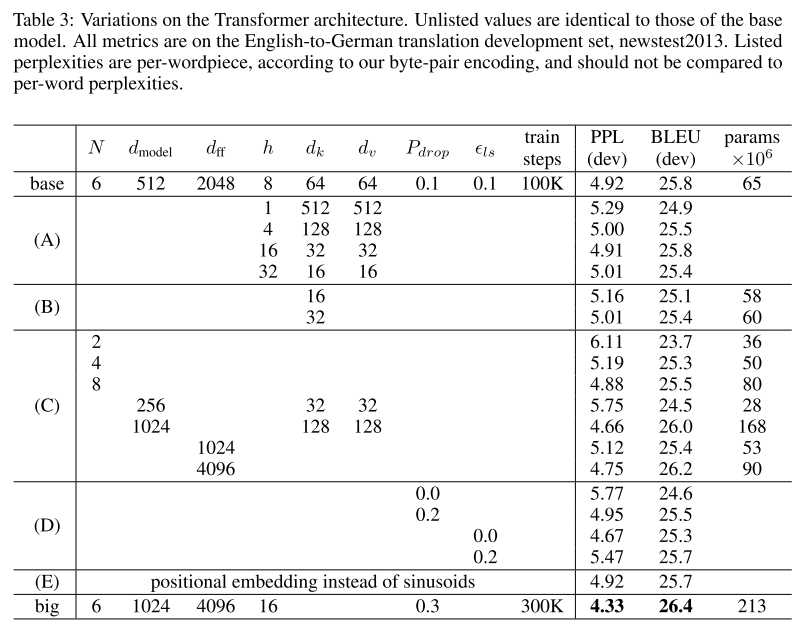
4-3. Ablation Study
Ablation study를 통해, Transformer model의 주요 구성 요소들이 전체 성능에 미치는 영향을 평가하였습니다. 이 연구는 Multi-Head Attention, Positional Encoding, Layer Normalization등 Transformer의 핵심적인 아이디어들이 model의 성능 향상에 기여함을 보여줍니다.
- 결론: Transformer model의 다양한 구성 요소들은 모두 model의 성능에 중요한 역할을 하며, 특히 Multi-Head Attention Mechanism은 복잡한 언어 구조를 이해하는 데 핵심적인 기여를 했습니다.
이상으로 포스팅을 마치겠습니다.
감사합니다.