Paper Review - [NAACL 2024] "Adaptive-RAG ; Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity", Soyeong Jeong et al., Mar 2024
Conference : NAACL, Mar 2024
1. Contributions
RAG System은 Question-Answering(QA) task를 비롯한 다양한 task들에서 LLM의 성능을 높이는 데에 기여를 해왔습니다. 그러나, 사용자들이 실제로 쓰는 query들의 complexity는 다양합니다. 때로는, 간단한 query에 대해서 Multi-Step Approach를 하면서 불필요한 계산을 할 때도 있고, 복잡한 query에 대해서는 Single-Step Approach를 하며 적절하게 다루지 못할 때도 있습니다. 이러한 문제를 위해서 본 논문에서는 query의 complexity를 LLM을 활용해 미리 분류하고 활용하는 방안으로 Adaptive-RAG를 제안했습니다. 논문의 핵심 기여는 다음과 같습니다.
1-1. 실제 사용자들이 쓰는 현실적인 query들은 complexity가 다양하다는 점을 지적했습니다.
1-2. LLM을 활용한 Classifier를 통해 query의 complexity를 평가하고, 각각의 complexity에 대해서 더 적절한 접근 방법들을 제안했습니다.
1-3. 특히, Adaptive-RAG를 통해서 complexity와 simplicity 사이의 균형을 맞추어 다양한 query들에 대해서 효율적으로 RAG가 작동할 수 있도록 했습니다.
‘When did the people who captured Malakoff come to the region where Philipsburg is located?’와 같은 query는 ‘The region where Philipsburg is located’, ‘The people who captured Malakoff’, ‘When did the people went the region’ 과 같은 여러 reasoning을 거치며 답변을 생성할 수 있어야합니다. 이러한 경우에는 Document에 여러 차례 접근하여 정보들을 연결하는 Multi-hop QA 방식으로 answer를 생성하는 것이 적절합니다. 논문에서는 query의 complexity에 따라서 1) document에 접근하지 않고 답변을 생성 2) Single-hop QA 3) Multi-hop QA 을 수행할 수 있도록 했습니다.
Multi-hop QA에 대한 직관적인 이해를 위해서 Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions, Harsh Trivedi et al., ACL23 에서의 사진을 한 장 첨부하겠습니다.
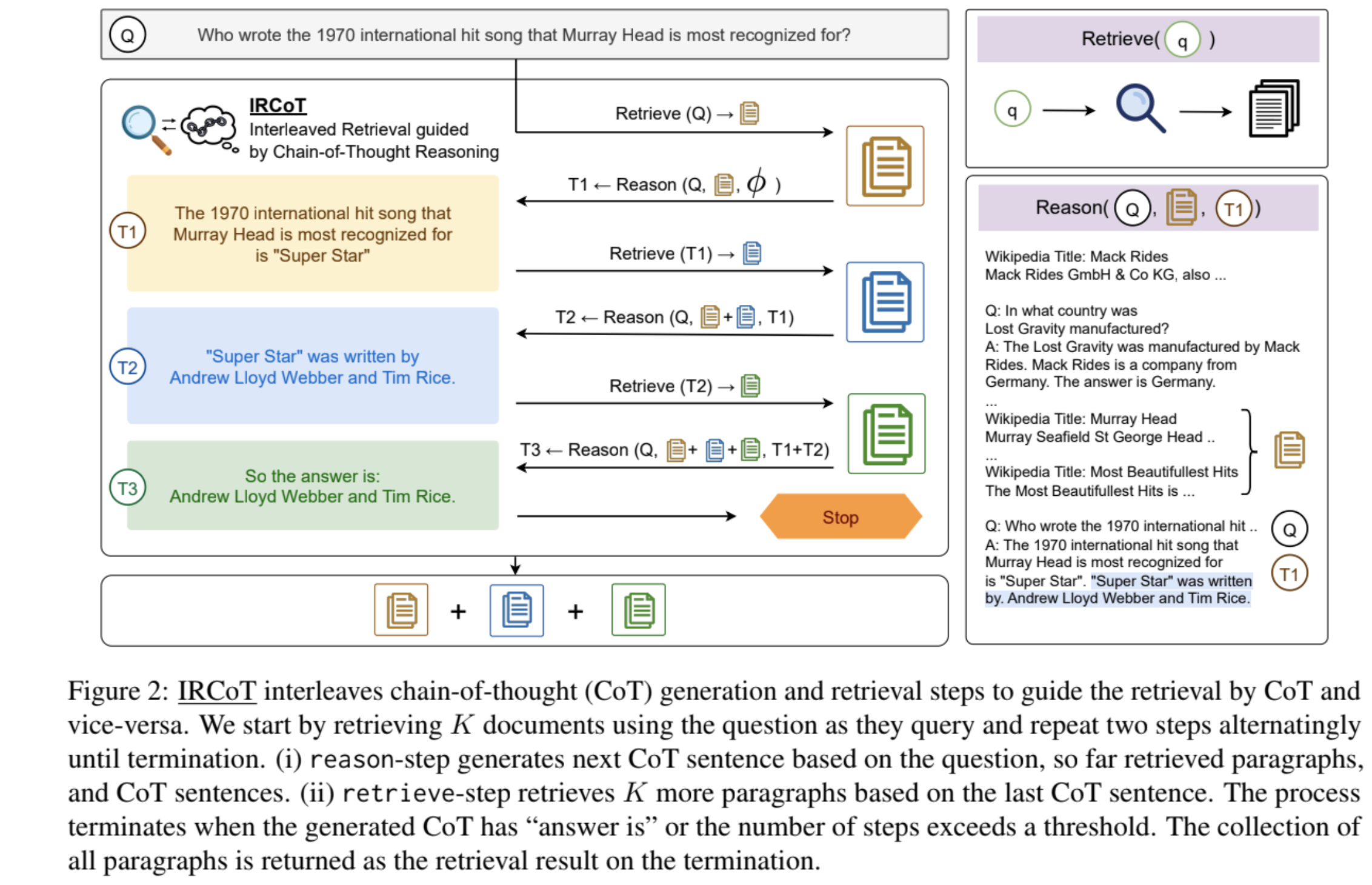
2. Backgrounds
2-1. Open-domain QA(ODQA)
Open-domain Question Answering (ODQA)는 주제나 도메인에 제한 없이 다양한 질문에 답변할 수 있는 system입니다. 이러한 system은 방대한 정보 source에서 정확한 답변을 찾아내야 하기 때문에, NLP, IR, ML 같은 여러 기술을 종합적으로 활용합니다. ODQA의 주요 도전 과제 중 하나는 정확도와 효율성을 균형 있게 유지하면서 다양한 형태의 질문에 대해 정확한 정보를 신속하게 제공하는 것입니다.
2-2. Single-hop QA vs Multi-hop QA
- 2-2-1. Single-hop QA
Single-hop QA는 질문에 답하기 위해 단일 정보 source나 문서에서 직접적으로 답을 찾을 수 있는 Question-Answering system을 말합니다. 이러한 system은 주로 간단하거나 구체적인 정보를 요구하는 질문에 효과적입니다. 예를 들어, “한국의 수도는 어디인가요?” 같은 질문은 직접적으로 답변할 수 있으며, 복잡한 추론이나 여러 정보 source의 결합이 필요하지 않습니다.
- 2-2-2. Multi-hop QA
Multi-hop QA는 여러 단계의 추론을 거쳐야 하거나 다수의 정보 소스를 종합해야만 답변할 수 있는 복잡한 질문에 초점을 맞춘 system입니다. 이러한 시스템은 하나의 문서나 정보 소스만으로는 충분한 정보를 얻을 수 없는 경우 사용됩니다. 예를 들어, “바이든이 졸업한 대학의 설립자는 누구인가요?”와 같은 질문에 답하기 위해서는 먼저 “바이든이 졸업한 대학”을 찾고, 그 다음에 해당 대학의 “설립자”에 대한 정보를 찾는 여러 단계를 거쳐야 합니다. 이 과정에서 여러 문서를 통합하고, 정보 간의 연결을 추론하는 과정이 필요합니다.
3. Methodology
3-1. Preliminaries
본 논문에서는 Adaptive-RAG의 방법론을 적용하기 위해서 Prompt에 따른 QA접근 방식을 ‘Non Retrieval for QA’, ‘Single-Step Approach for QA’, ‘Multi-step Approach for QA’ 3가지로 나누었습니다.
- 3-1-1. Non Retrieval for QA
Non Retrieval for QA에서는 Document를 참고하지 않고, 오로지 LLM으로만 답변을 생성하도록 하는 것입니다. Retrieving을 하는 과정이 필요없이 때문에, computation관점에서 효율적이게 됩니다.
Input query : $x = [x_1, x_2, \ldots, x_n]$
Generated output : $\bar{a} = y = \text{LLM}(x) = [y_1, y_2, \ldots, y_n]$
그러나, LLM에 근거해서 답변을 하게 되는 것이기 때문에, query가 simple한 경우에 적절한 접근방식이 됩니다. 따라서, 본 논문에서는 query가 simple로 분류된 경우에 Non Retrieval for QA방식을 채택합니다.
- 3-1-2. Single-step Approach for QA
LLM 자체만으로는 qeury에 답변하기 힘든 경우에는 1차례 document에 접근하여 external knowledge $d$를 검색해오는 방식으로 답변을 생성하게 됩니다. Wikipedia와 같은 전체 external knowledge source를 $D$라고 하고, Query를 $q$라고 denote하면
\[d = \text{Retriever(q;D)}\]와 같이 $d \in D$를 검색하고, $\bar{a} = \text{LLM}(q,d)$를 통해서 답변을 생성하게 됩니다.
- 3-1-3. Multi-step Approach for QA
Query가 synthesizing information과 같이 reasoning을 하면서 다양한 document를 참고해야 할 때에는 Single-step Approach만으로는 충분하지 않은 경우가 있습니다. 이러한 경우에 Multi-step Approach를 통해서 LLM에 더 다양하고 적절한 document를 제공해주는 과정이 필요합니다.
Retriever가 $i$번 째에 검색해온 document는 $d_i = \text{Retriever}(q,c_i ;D)$이며, \(c_i = (d_1,d_2,\ldots,d_{i-1}, \bar{a}_1, \bar{a}_2,\ldots, \bar{a}_{i-1})\)라고 할 때, $\bar{a}_i = \text{LLM}(q,d_i,c_i)$로 답변을 생성하게 됩니다. 즉, $i$번 째 retrieving 과정에서 query $q$와, $i$번 째 retrieved document와 그 이전 시점의 모든 retrieved documents 그리고 모든 generated answer를 토대로 새로운 $i$번 째 answer를 생성하게 됩니다. 이와 같은 과정을 거치게 되면, LLM이 답변을 생성함에 있어서 중요한 정보들을 document를 통해서 얻을 수 있게 되지만, computation cost는 증가하게 됩니다.
답변의 정확성과 computation사이의 밸런스를 잘 유지하기 위해서, 위의 3가지 접근 방식을 query의 complexity에 따라서 적절하게 적용해야 합니다. 이를 Adaptive-RAG에서는 LLM을 통해 complexity를 분류하고 적절한 접근 방식을 채택합니다.
3-2. Adapting Retrieval-Augmented LLMs
3-2-1. Query Complexity Assessment
본 논문에서는 LLM을 학습하여 query의 complexity를 분류하는 classifier로 활용합니다.
\[o = \text{Classifier}(q), \quad o \in{\{A,B,C\}}\]주어진 query $q$를 classifier에 넣어줌으로 ‘A’, ‘B’, ‘C’로 class를 분류하게 되며, ‘A’는 Simple query로 No retrieval Approach($\bar{a} = \text{LLM}(q)$)를 적용하고, ‘B’는 moderate complexity query로 Single-step Approach($\bar{a} = \text{LLM}(q,d)$)를 적용하며, ‘C’는 complex query로 Multi-step Approach($\bar{a} = \text{LLM}(q,d,c)$)를 적용합니다.
3-2-2. Training Strategy
위의 Classifier를 학습시키기 위해서 (query, complexity) pair로 구성된 annotated dataset이 필요하지만, 논문에서는 traning dataset을 자동적으로 만들어주는 방법론을 제시했습니다. 논문에서 처음에 시도했던 방법론은 다음과 같습니다.
만일 Non-retrieval based approach로 인해 생성된 답변이 정답으로 잘 생성이 되었다면, 해당 query에 대해서는 ‘A’ class를 부여해줍니다. 반면에, Non-retrieval based approach로는 올바른 답변을 생성해내지 못한 반면, Single-step approach와 Multi-step approach에서 동일한 올바른 답변을 생성해내면 query에 ‘B’를 부여해줍니다.
그러나 위와 같은 방식으로는 Multi-step approach를 했음에도 올바른 정답을 생성하지 못하는 query에 대해서는 labeling이 어려워진다는 문제가 있습니다. 논문에서는 Non-retrieval based approach로 적절한 답변을 생성한 query에 대해서는 ‘A’를 부여하고 나머지에 대해서는 ‘B’를 부여했으며, Multi-hop dataset에 대해서는 ‘C’를 부여하는 방식으로 annotation을 진행했습니다.
결과적으로, 각각의 query에 대해서 모두 labeling이 되었고, 이러한 dataset을 토대로 Classifier를 학습해주었다고 합니다.
4. Empirical Results
4-1. Datasets
Adaptive-RAG의 에서는 query의 complexity를 다루기 위한 다양한 ODQA Dataset이 사용되었습니다. 사용된 dataset은 single-hop과 multi-hop query에 걸쳐 있으며, 각각의 dataset에 대한 자세한 설명은 다음과 같습니다.
4-1-1. Single-hop QA dataset
- SQuAD v1.1: Stanford 대학에서 제작한 이 dataset은 wikipedia 기사를 기반으로 한 10만 개 이상의 Question-Answer pair를 포함하고 있습니다. 각각의 query들은 특정 문서 내에서 정답을 찾아낼 수 있으며, model이 문서에서 정확한 답변을 추출하는 능력을 평가합니다.
- Natural Questions: Google에서 제공하는 이 dataset은 실제 사용자가 Google 검색을 통해 제출한 query과 wikipedia로부터 추출된 답변으로 구성됩니다. Query은 다양한 형태와 복잡성을 가지며, model은 각 query에 대한 답변을 찾아내는 task를 하는 것이 목적입니다.
- TriviaQA: 일반 지식 퀴즈 질문과 web source 및 wikipedia 페이지로부터 추출된 문서로 구성된 dataset입니다. 다양한 주제에 걸쳐 있는 query은 모델의 범용성과 정보 검색 능력을 시험합니다.
4-1-2. Multi-hop QA dataset
- MuSiQue: 복잡한 query에 답하기 위해 여러 문서에서 정보를 종합해야 하는 multi-hop QA의 task를 제공합니다. 각 query들은 여러 reasoning 단계를 거쳐야 하며, model은 연관된 문서들 사이의 관계를 이해하고 정보를 통합하는 능력이 요구됩니다.
- HotpotQA: 이 dataset은 query에 답하기 위해 둘 이상의 문서에서 정보를 연결해야 하는 scenario를 포함하고 있습니다. 각 query들은 model이 여러 문서에 걸쳐 있는 정보를 합성하고, 복잡한 추론을 수행할 수 있는지 평가하는 데 사용됩니다.
- 2WikiMultiHopQA: 두 개의 wikipedia 문서를 사용하여 질문에 답변을 요구하는 multi-hop QA dataset입니다. Model은 두 문서 사이의 연결 고리를 찾아내고, 각각의 문서에서 얻은 정보를 합쳐 질문에 답변해야 합니다.
각 dataset은 모델이 다양한 복잡성과 형태의 query에 효과적으로 대응할 수 있는지를 평가하는 데 중요한 역할을 합니다.
4-2. Models
Adaptive-RAG의 평가는 다양한 질문 유형에 대한 처리 능력을 검증하기 위해 여러 대조 model과 함께 이루어졌습니다. 이 model들은 다음과 같이 세 가지 범주로 분류됩니다: Simple, Adaptive, Complex.
- Simple Approaches
- No Retrieval: 이 접근 방식에서는 external document를 검색하지 않고, 오로지 LLM만을 사용하여 query에 대한 답변을 생성합니다. 이 방법은 처리 속도가 매우 빠르지만, LLM이 가진 지식의 한계로 인해 복잡한 질문이나 최신 정보를 요구하는 질문에는 적합하지 않을 수 있습니다.
- Single-step Approach: query에 대응하기 위해 단일 문서 검색을 수행하고, 검색된 문서를 바탕으로 답변을 생성하는 방식입니다. 이 접근 방식은 대부분의 single-hop 질문에 효과적이지만, 여러 문서에서 정보를 종합해야 하는 복잡한 질문에는 한계가 있습니다.
- Adaptive Approaches
- Adaptive Retrieval: 이 모델은 query의 복잡성을 평가하여 필요한 경우에만 문서 검색을 수행하는 방식으로, 자원 사용을 최적화합니다. 그러나 복잡한 질문을 처리할 때 필요한 다중 문서 검색과 같은 고급 기능은 지원하지 않습니다.
- Self-RAG: 본 모델은 적응형 검색을 지원하며, 질문에 가장 적합한 전략을 자동으로 선택합니다. Self-RAG는 질문의 복잡성을 동적으로 판단하고, 필요에 따라 Multi-hop 검색을 포함한 다양한 전략을 적용할 수 있습니다.
- Adaptive-RAG (논문에서의 model): 질문의 복잡성을 분류하고, 이에 기반해 가장 적절한 검색 및 답변 생성 전략을 선택하는 새로운 적응형 framework입니다. Adaptive-RAG는 다양한 복잡성의 질문에 효과적으로 대응할 수 있으며, 전체적인 효율성과 정확성을 극대화합니다.
- Complex Approaches
- Multi-step Approach: 복잡한 질문에 대응하기 위해 여러 차례에 걸쳐 문서 검색과 정보 합성을 수행하는 방식입니다. 이 접근 방식은 Multi-hop query에 매우 효과적이지만, 처리 시간이 길고 자원 소모가 큰 단점이 있습니다.
각 접근 방식은 query에 대한 답변 생성 시 고려해야 할 특정 장단점을 가지고 있으며, 이러한 다양한 모델을 비교함으로써 Adaptive-RAG의 유용성과 효과성을 입증했습니다.
4-3. Reseults
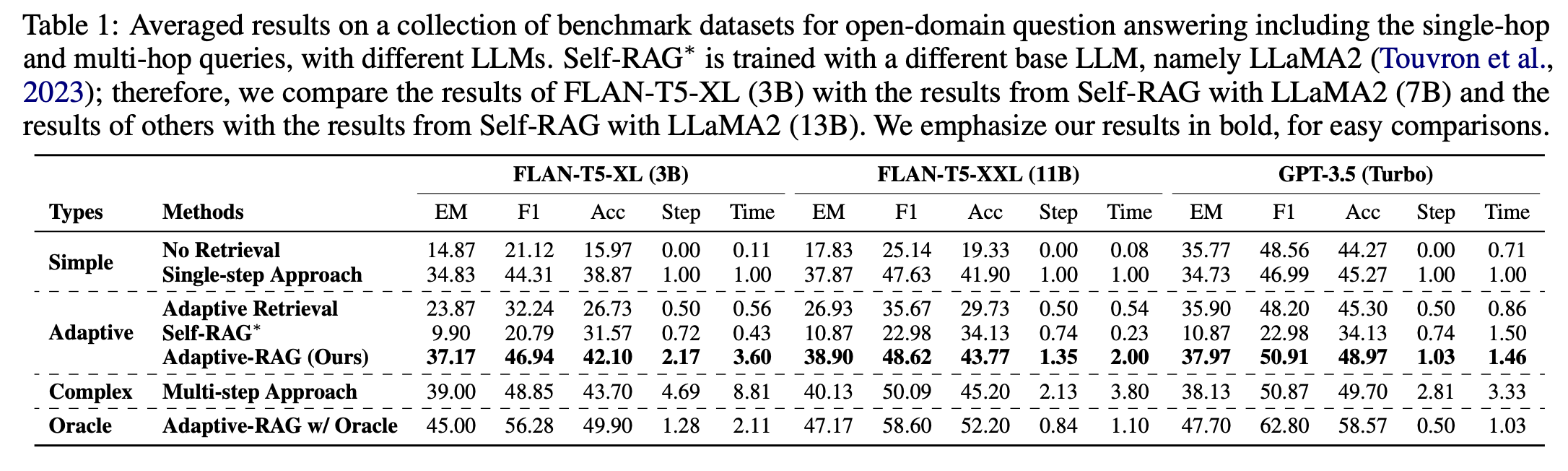
Adaptive-RAG는 single-hop 및 multi-hop dataset 모두에서 뛰어난 성능을 보여주며, 다양한 복잡성의 query들을 처리할 수 있는 그 범용성을 강조했습니다. 특히, 기존의 adaptive model과 multi-step approach에 비해 정확성과 효율성 측면에서 우수한 성능을 나타냈습니다.
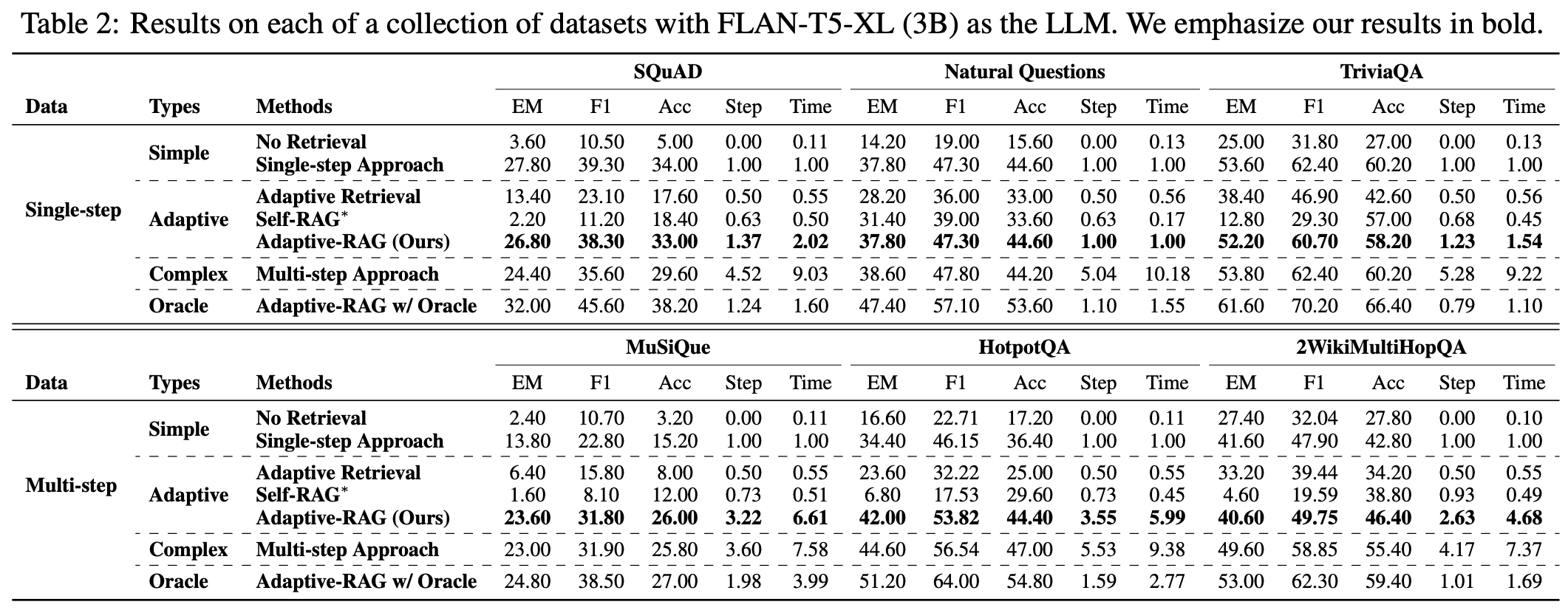
특히, 대부분의 Dataset에서 Adaptive-RAG가 더 좋은 성능을 보인다는 점에서 흥미로웠습니다. Multi-hop을 요구하는 dataset에서는 step과 time이 높게 나오는 것을 통해서 classifier로 쓰이고 있는 LLM도 training이 잘 된 것으로 보여집니다.
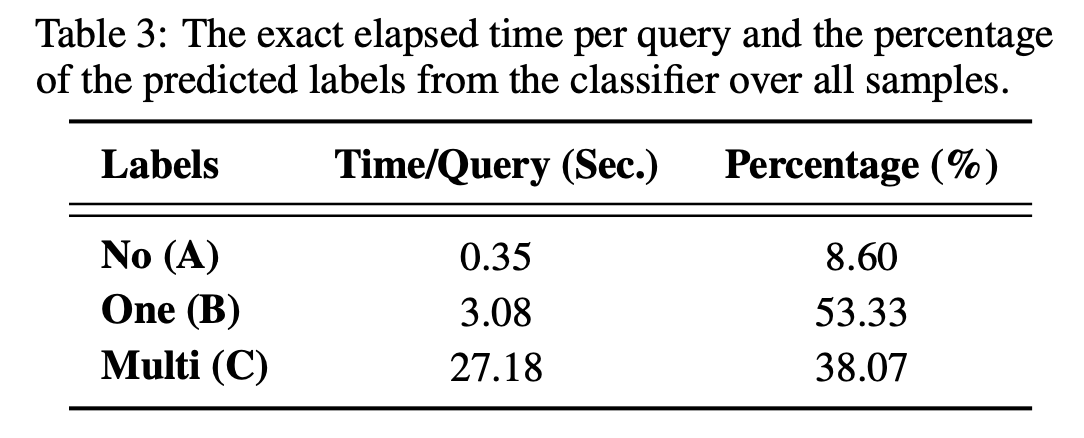
Multi-step Approach에서는 시간이 27초 정도가 걸린다는 것을 확인할 수 있습니다. 이렇게 시간을 소요함으로 정확도는 올라가지만, 27초는 여전히 긴 시간이라고 판단됩니다. Multi-step에 있어서 시간을 단축시키는 연구방향도 생각해볼 수 있을 것 같습니다.
마지막으로 Adaptive-RAG는 어떠한 방식으로 reasoning을 하게 되는지에 대한 case study를 확인하겠습니다.

이상으로 포스팅을 마치겠습니다.
감사합니다.